
英伟达60B双塔模型提速生成,并行文本效率翻倍
骨干网络改造,复用预训练权重,无需从零完整训练,大幅降低开发成本。双塔架构,分工并行提升生成效率串行输出,双塔架构可并行写入文本,大幅拉高推理吞吐量,兼顾速度与输出效果。该模型采用英伟达专属开源协议开放权重,开发者可自由下载测试、商用部署。显卡,单卡仅支持纯自回归模式,双塔完整推理需双卡协同。
大模型生成慢 痛点终于有解了
行业痛点在于, 大模型生成文本的速度迟缓, 用户等待一个回答, 需耗费几秒乃至几十秒, 体验极为糟糕。英伟达瞅准了此矛盾之处, 于7月2日推出Labs离散扩散语言模型, 旨在专门解决逐Token生成速度缓慢的问题。该模型的权重已在开源平台予以开放, 开发者能够直接进行下载并使用。此套方案并非从零开始构建, 而是基于现有的骨干网络实施改造, 复用预训练权重, 极大地降低了开发成本。
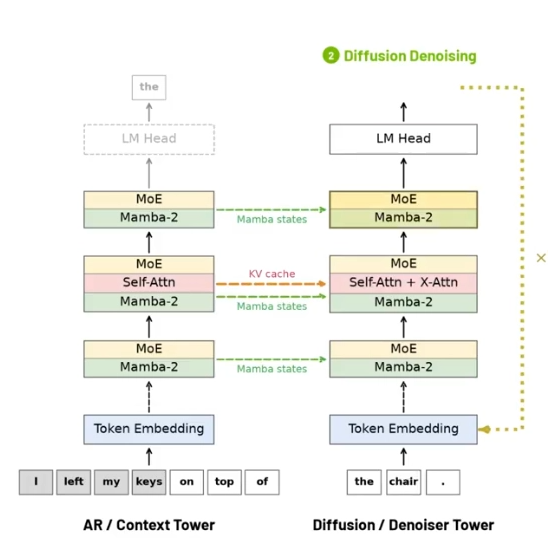
双塔分工 各管各的活
这座模型的总参数量为60B, 然而它被拆分成了两座各个为30B的独立神经网络, 两座塔各自激活3B参数, 并且搭载着128个可路由专家模块, 这似乎相当于两个大脑各自带着一个专家团队, 上下文塔处于固定被冻结的状态, 负责任记住全文的语义信息, 如同档案馆一般不参与生成, 去噪塔专门进行训练, 依靠扩散机制并行生成文本, 这与传统的逐字生成方式完全不一样, 两塔借助交叉注意力机制互相通数据, 一座管记忆, 一座管输出。
并行写入 速度翻倍
传统模型会逐个Token串行输出, 写一个字便等待一个字, 如同排队过独木桥, 双塔架构能够并行写入文本, 多个位置同时进行生成, 推理吞吐量被大幅拉高, 多类基准测试数据表明, 就是模型综合能力保留了原版百分之九十八点七的水准, 等同于质量几乎没有出现下降, 然而文本生成吞吐速度提高了二点四倍, 用户等待回答的时间锐减一大半, 唯有代码和数学类任务出现小幅下滑, 其他任务均表现良好。
开源协议 商用无阻
英伟达此次运用专属开源协议来开放权重, 开发者能够自由进行下载去测试, 并且还能够用于商用部署, 不存在额外的限制。这对于那些想要快速实施落地AI产品的公司而言是一则好消息, 无需自身从零基础开始训练大模型, 直接借助这套权重去做微调就行了。然而部署是需要硬件给予支持的, 运行的时候必须搭配双张H100或者A100 80GB显卡。单卡仅仅只能运行纯自回归模式, 双塔完整推理非得双卡协同作业才行。
测试全面 能力持平
覆盖多项任务的模型测试, 包含常识问答、数学推理、代码生成、阅读理解等。绝大多数指标和原版自回归模型基本持平, 这表明并行生成并未过多牺牲性能。实际使用中, 用户或许感觉不到回答质量有差异, 然而等待时间显著变短。英伟达于官方文档里展示了详细对比数据, 凭借具体数字证实了速度提升以及质量保留的效果。
落地场景 一步到位
这套模型适用于诸如实时对话系统、智能搜索、内容生成等对速度有着较高要求的场景, 举例来说, 像客服机器人这种情况, 以往用户问完问题后得等3秒才能看到滚动生成的内容, 现今, 在1秒内就能看到完整的回答, 对于开发者而言, 拿到权重后可直接于双卡服务器上进行部署, 无需去修改代码, 英伟达还给出了推理优化工具, 用以协助开发者进一步去压榨硬件性能, 将速度推至极限。
若是此刻你打算去部署那么一套大模型服务, 你会鉴于那2.4倍的速度提升, 特意去配备两台H100显卡以便运行这个开源模型吗, 欢迎于评论区留言去分享你的选择, 点赞以及转发从而让更多人瞧见这个新方案?
