阿里联合人大开源多领域科学生成基础模型LOGOS,参数效率极高
以纯序列建模范式,一致性地匹配或超越了领域专用方法。传统范式中,换一个研究环节(比如从结构预测换到分子生成),往往就得换一套新模型和新假设。,这种“学用脱节”导致模型落地时需要大量微调。gap,无需复杂的适配层或大量微调即可激活生成能力。
一个模型搞定六大科学任务
6月18日这一天, 阿里巴巴同中国人民大学携手联合进行了开源行动, 所开源的是一个被称作LOGOS的基础模型, 此模型具备能够同时对六大具有代表性科学任务予以处理的能力, 像预测蛋白质结构、生成小分子之类的任务, 举例来说就是如此。在测试期间, 它运用纯序列建模这种方式进行操作, 其性能呈现出一致性的表现, 追平了还甚至超越了那些专门针对单个任务而设计的旧有方法。以往的时候, 科学家面对不同任务之时需要更换不同的模型, 现如今, 一个模型便能够将这些任务全部搞定, 这样大大地使得研究流程得到了简化。
参数效率惊人:1B打赢56倍参数量
在LOGOS之中, 最能吸引目光的数据, 是参数效率。其1B参数版本, 在多个任务方面, 居然超越了微软的8×7B模型, 且参数量仅仅是后者的56分之一。这究竟意味着什么呢? 在同等计算资源的情况下, LOGOS能够运行得更快, 而且成本更低。对于众多高校以及中小型科研机构而言, 这直接使得使用门槛降低, 无需花费高昂价格购买顶级显卡, 便能运行顶尖的AI模型。
把蛋白质和分子都翻译成同一种语言
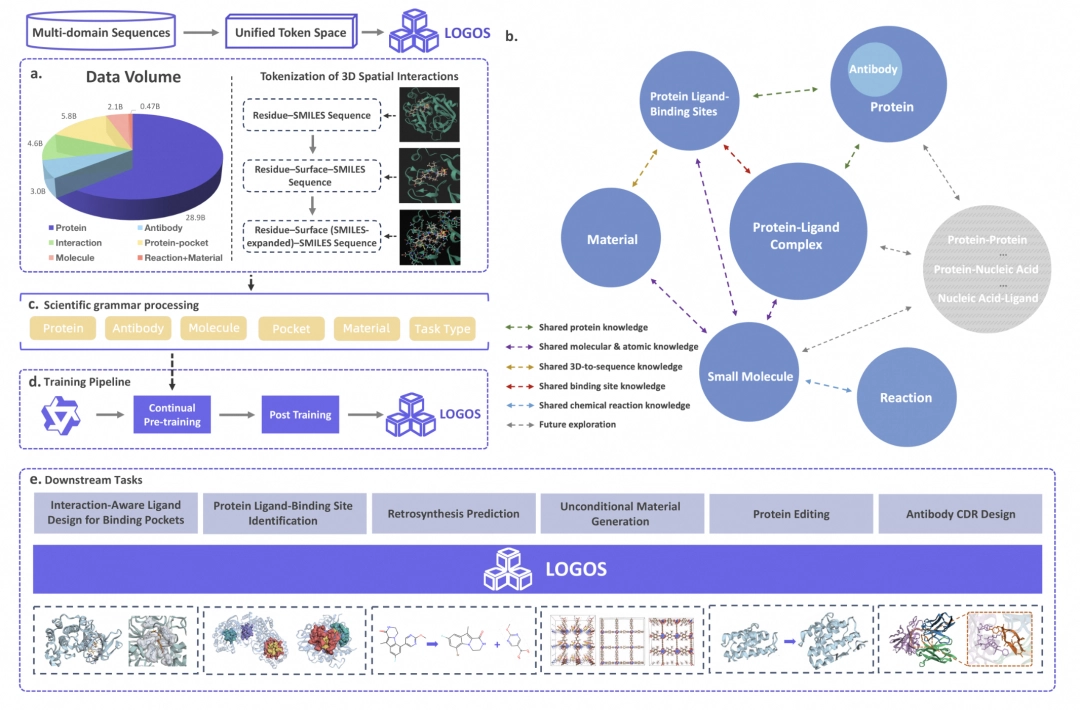
以往的时候, 蛋白质、小分子、材料这些科学研究的对象, 各自运用不一样的数据格式, 如同不同国家的人们说着不同的方言那般。LOGOS设计出了一套共享词表, 将它们全都转变成为统一的离散Token序列。如此一来, 原本处于“鸡同鸭讲”状况的异构对象, 便能够在同一个生成空间里被大模型所理解以及生成。这恰似给所有的科学对象配备了一个同声传译器, 使得它们能够直接进行对话。
不靠3D坐标,靠“读文字”理解空间结构
需明确的是, 传统AI若要理解蛋白质以及小分子二者是怎样结合的, 那必然得依靠复杂的3D坐标, 还有几何神经网络才行。而LOGOS发明了“文字描述法”, 这种方法是将3D空间当中的接触模式直接“语法化”为离散的Token。该模型根本无需输入3D坐标, 仅仅凭借序列预测, 便能够在脑海里构建出复杂的3D空间互作规律。这就等同于把三维立体地图简化成文字说明一般,大幅降低了计算的复杂度。
彻底解决“学用脱节”的老问题
在老方法里, 预训练模型所学到的知识跟下游具体的任务之间常常存在偏差, 这致使在落地的时候需要进行大量的微调。LOGOS凭借统一的科学语法设计, 将预训练与下游应用之间的差距给消除掉了。它无需复杂的适配层, 也不需要大量的微调, 就能够直接激活生成能力。这情形如同学生学完基础知识之后, 不需要额外去补习, 就能够直接参加各类考试, 效率得到了大幅的提升。
开源全部代码,欢迎所有人来用
LOGOS此次将模型权重、推断代码以及技术报告完整地进行了开源, 任何一个人都能够去下载并加以使用, 这就表明在全球范围内的科研人员都能够免费得到这套工具, 在药物研制、新型材料设计等方面迅速地开展实验, 不管是大学实验室, 还是初创公司, 均能够依据LOGOS来开展二次开发, 以此加速科学发现。
读完这篇文章之后, 你认为在AI将“科学语法”统一起来以后, 最有可能率先对哪个行业造成颠覆? 欢迎于评论区留言展开讨论, 同样也不要忘记给诸多朋友点赞以及转发。