
谷歌新模型本地推理快4倍,DiffusionGemma开放下载
该架构在云端批处理场景下效率较高,但在本地推理时受限于内存带宽,存在计算资源浪费问题。模型相当,但推理效率显著更高。下载模型权重。质量方面,模型还支持迭代优化,能在生成过程中主动纠正错误,输出更加稳定一致。20.0%,展现出扩散架构在推理任务上的潜力。不过模型在部分基准上仍存短板。
谷歌突然发布新模型,速度提升四倍
于昨日, 也就是6月11日, 谷歌官方宣称推出全新的开放AI模型, 该模型基于文本扩散机制, 相较于传统自回归模型, 其在本地推理速度方面直接实现了4倍的提升, 此消息是由网友乌蝇哥的左手以及华南吴彦祖提供出来的线索, 对于开发者以及AI爱好者而言, 这毫无疑问又是一个重大利好, 这意味着本地部署大模型将会变得更快且更高效。
扩散模型到底是个什么东西
简要来讲, 传统的自回归模型, 是如同读书那般, 逐字逐句依照顺序来生成内容, 于云端服务器之上, 运行效率还说得过去, 但当在普通电脑上运行之时, 会因内存带宽受限, 导致出现大量的计算浪费情况。而此次谷歌所推出的扩散模型, 则全然不一样, 它先是随机产出一堆噪声, 接着借助一步步地去噪操作, 一次性并行处理全部文字, 随后逐步优化整体质量。这样的设计, 使其在本地低带宽环境里, 具备显著的速度优势。
开源许可和下载渠道都已就绪
谷歌宣称, 此新模型具备的能力会同其他Gemma 4系列模型等同, 然而推理效率显著更为高些。该模型凭借Apache 2.0许可证予以开源, 这表明开发者能够自由地去进行使用、修改以及商用。用户目前就能够径直从Hugging Face平台下载模型权重, 便利且快速地整合至自身项目里。谷歌此次于开源方面做得极为妥当, 未设置过多的限制。
迭代纠错能力让输出更稳定
这款扩散模型具备支持迭代优化的特性, 在生成进程里能够主动察觉并改正错误, 进而输出更为稳定一致的结果。依据官方给出的数据, 采样速度已然达到每秒1479个token, 而整个过程所产生的开销仅仅只需0.84秒。这样的效率提升对于那些有着快速响应需求的本地应用场景而言极为关键, 像是个人电脑运行代码助手或者文本生成工具之际, 用户几乎难以感受到等待的时长。
代码和数学表现各有亮点
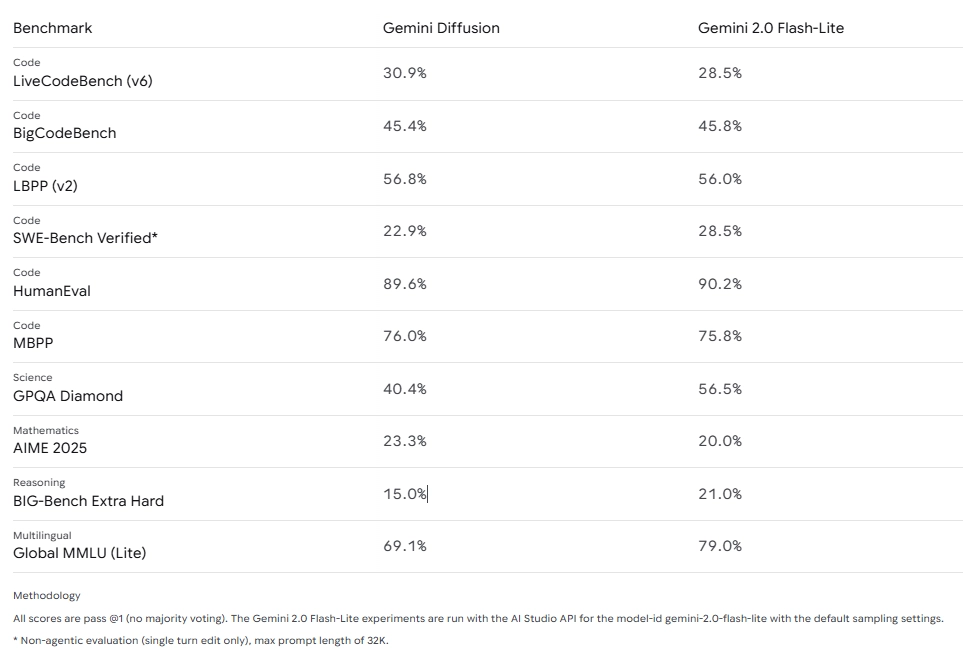
在代码生成的测试里, 此模型于HumanEval上获取了30.9% 的得分, 于MBPP上达到了45.4%, 于BigCodeBench上得到了89.6%, 和Gemma 2.0 Flash-Lite各有输赢。它在数学能力层面的表现格外突出, 在AIME 2025测试中拿到23.3%, 显著高于对比模型的20.0%, 这表明扩散架构在推理任务上的确具备独特的潜力。不过, 在某些基准方面, 仍然存在短板, 举例来说, 科学推理GPQA Diamond仅仅只有40.4%, 这一比例远远低于对比模型的56.5%。
英伟达GPU能充分发挥并行优势
英伟达官方发布的博文表明, 设计此扩散模型能够充分运用其GPU所具备的Tensor Core并行计算能力, 实测得到的数据展示出, 在单块H100 GPU的情况下, 模型生成速度能够达到每秒1000个token, 在DGX Spark上则是每秒150个token, 而在DGX Station上, 更是可以达到每秒2000个token, 这个速度大约是同等条件下自回归模型速度的4倍, 对于拥有高性能显卡的用户而言, 这意味着一台家用电脑能够跑出接近云端服务的速度。

你是不是正于本地开展大模型的部署工作? 你认为4倍的速度提升对你每天进行的开发工作能产生多大的助力? 欢迎在评论区域分享你所拥有的使用体验, 点赞以及转发从而让更多的开发者得以看到这一好消息!
