
苹果WWDC发布CoreAI引擎,取代旧框架,专为端侧大模型推理优化
框架,主打端侧大模型推理。场景,重点优化设备端大语言模型推理,重点支持更灵活的模型格式和更大的模型内存占用。是苹果生态中的一个机器学习框架,更偏向研究、训练和微调任务,常被开发者拿来测试和部署本地大模型。横向对比其他厂商方案,针对特定模型深度优化的引擎依然更容易胜出。
苹果WWDC 2026发布新端侧推理引擎
在2026年6月10日, 那时举办了全球开发者大会, 就在这个大会上, 苹果正式推出了全新推理引擎, 这个全新推理引擎是为了接替已服役9年的Core ML框架。新引擎主打端侧大模型推理, 其针对设备端本地运行大语言模型做了深度优化。苹果做出的这一举措意味着在AI基础设施方面迈出了关键一步, 特别是对于普通用户来讲, 未来手机上运行AI应用的速度会显著提升, 运行AI应用的效率也会显著提升。
旧框架Core ML已服役9年面临淘汰
Core ML自2017年加以推出之后, 主要是对图像分类这样的一类小型静态任务予以处理, 其模型规模一般仅仅只有几十兆字节。跟着大语言模型参数急剧飙升至数十亿, Core ML渐渐显得力有不逮, 无论是内存占用方面还是计算效率方面都没办法满足需求。苹果工程师于WWDC上直接表明, 旧框架的设计理念已然无法适应现代AI工作负载。
新引擎专注端侧大模型本地推理
新推出的引擎, 是专门针对设备端, 大语言模型推理论场景而设计的, 重点在于优化了模型格式灵活性, 以及内存管理, 它支持更大容量的模型, 在iPhone和Mac上运行又配合苹果神经引擎, 实现高效计算, 相比Core ML只能处分小模型, 新引擎能够顺畅运行70亿参数以上的模型, 让用户直接在手机上进行文本生成, 以及对话。
首批基准测试小模型提速明显
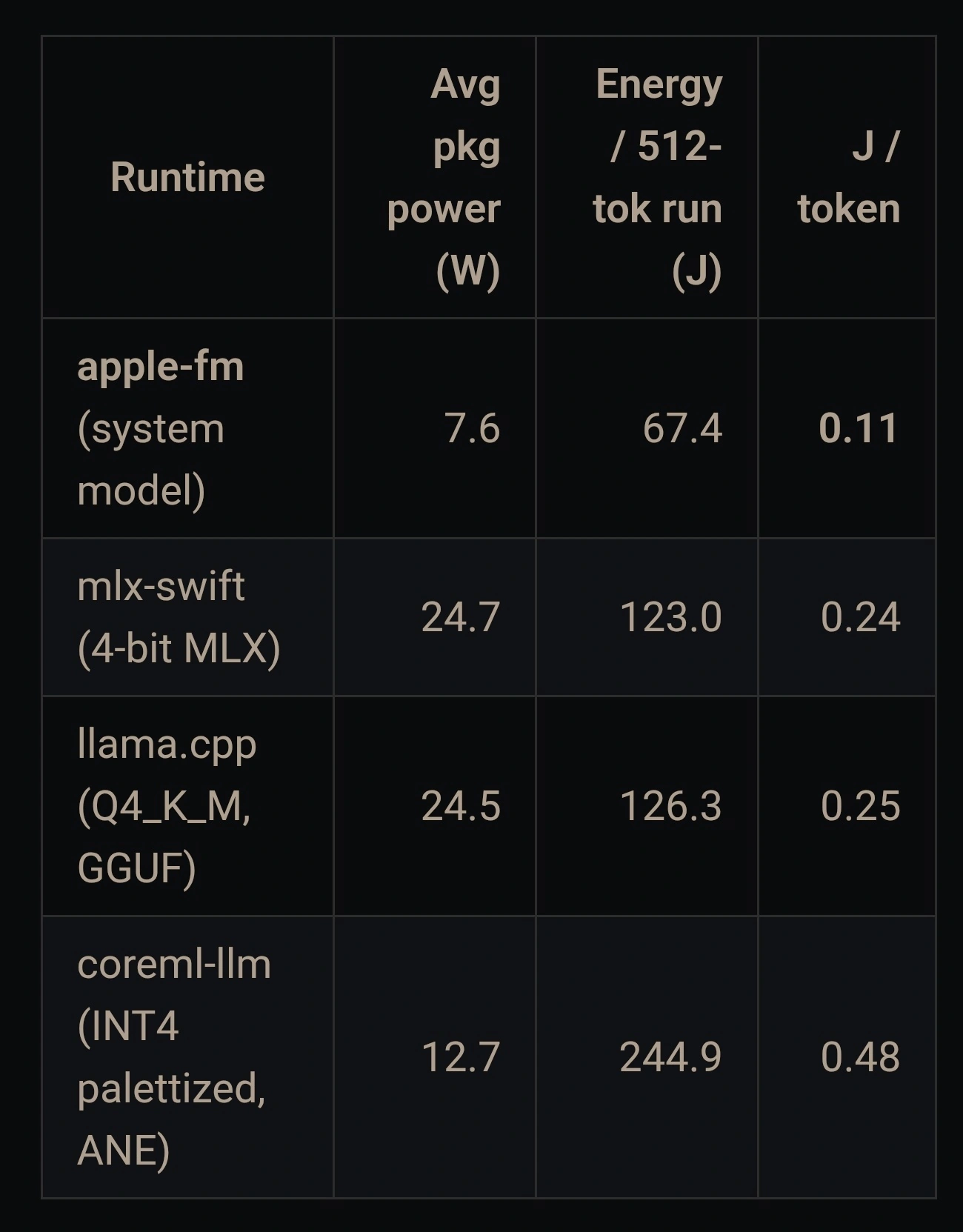
于M4 Mac之上对0.6B参数的Qwen3小模型予以测试之际, 新引擎的解码速度达至每秒约300个token之数, 此乃MLX框架的2.47倍。于iPhone 17 Pro之上, 这一优势约为1.6倍。解码速度直接对用户等待时间起到决定作用, 小模型场景下的提升表明日常AI问答、写作辅助等功能将会响应得更快。测试工程师于苹果库比蒂诺总部展开了多轮验证。
大模型性能接近MLX但优势收窄
当模型规模提升到八十亿参数的时候, 新引擎比起 MLX 仅仅快百分之五, 二者的解码性能差不多是一样的。这意味着新引擎的性能优势随着模型规模的增大而变窄, 主要是因为大模型需要更多的内存带宽以及计算资源。然而, 在持续负载测试当中, 新引擎与神经引擎的组合在性能保持率方面反而超过了, 长时间运行以后降频的情况更少。
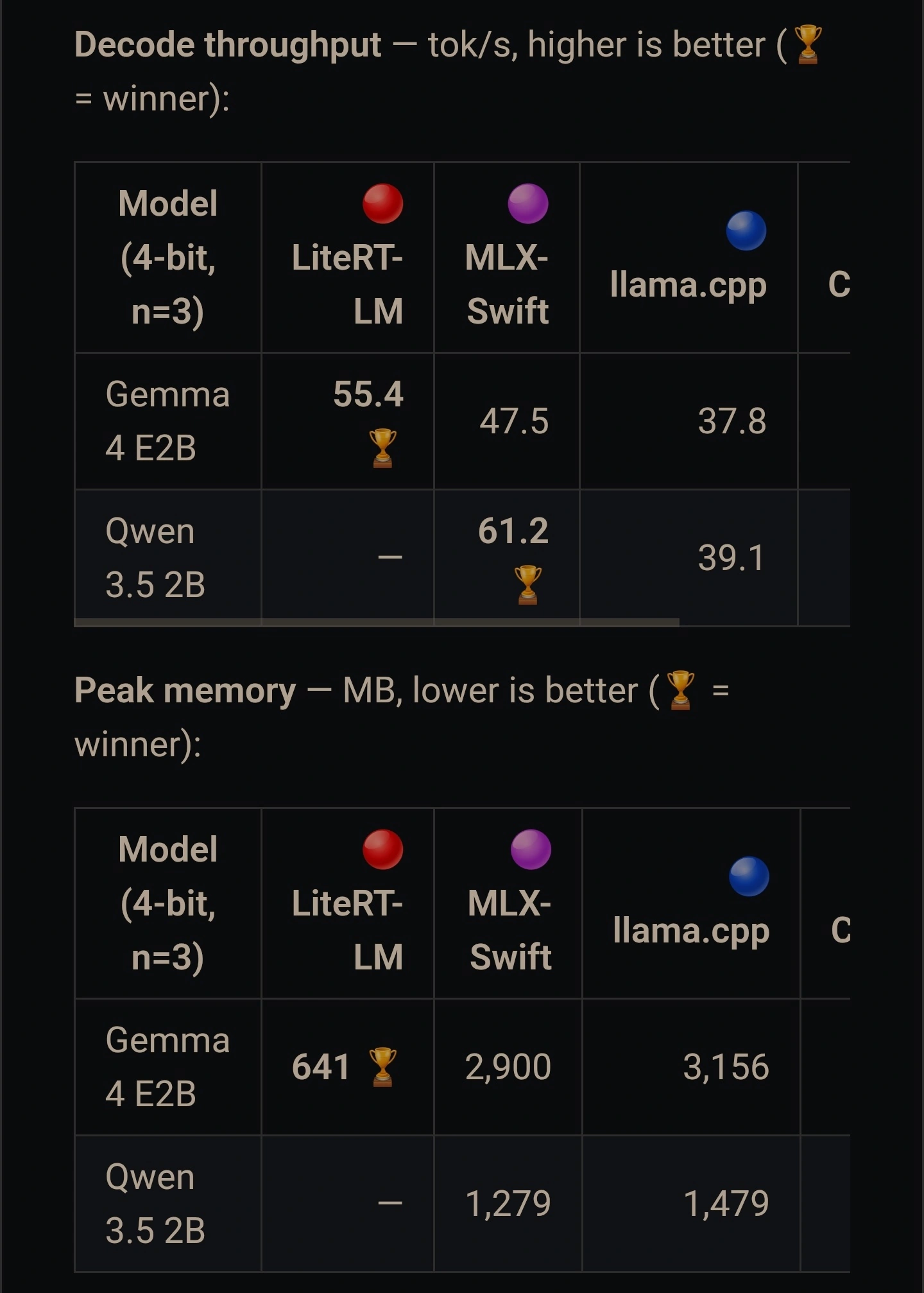
横向对比谷歌方案各有优劣
当谷歌的G-LM引擎运行Gemma模型那当儿, 在iPhone 17 Pro上能达到每秒55.4个token, 并且内存占用仅仅641MB。然而苹果MLX框架的内存占用却高达2900MB, 是前面所说的前者的4.5倍。这表明针对特定模型深度进行优化的第三方引擎仍旧有着明显的优势。苹果新引擎目前还需要时间去积累专属的优化经验, 不过端侧推理路线已经被行业所公认了。
通读完此篇后, 你认为苹果新研发的引擎有没有可能在一整年的时间跨度里, 追赶上谷歌G – LM所具备的优化水准? 欢迎于评论区域分享你个人的见解, 通过点赞以及收藏的行为, 使得更多人能够看到这一关于技术方面的对比情况。
