
阿里千问新模型全球第五,国产第一,全平台免费可用
千问旗舰模型 Qwen3.7-Max 已经正式上线,同步接入千问APP、PC端和网页端, 全部免费 。阿里这次直接把旗舰模型放进千问APP免费开放,是把竞争维度从「谁更便宜」拉到「谁的免费版更顶」。对普通用户来说,免费用上全球第五的模型,门槛几乎为零。
全球第五国产第一意味着什么
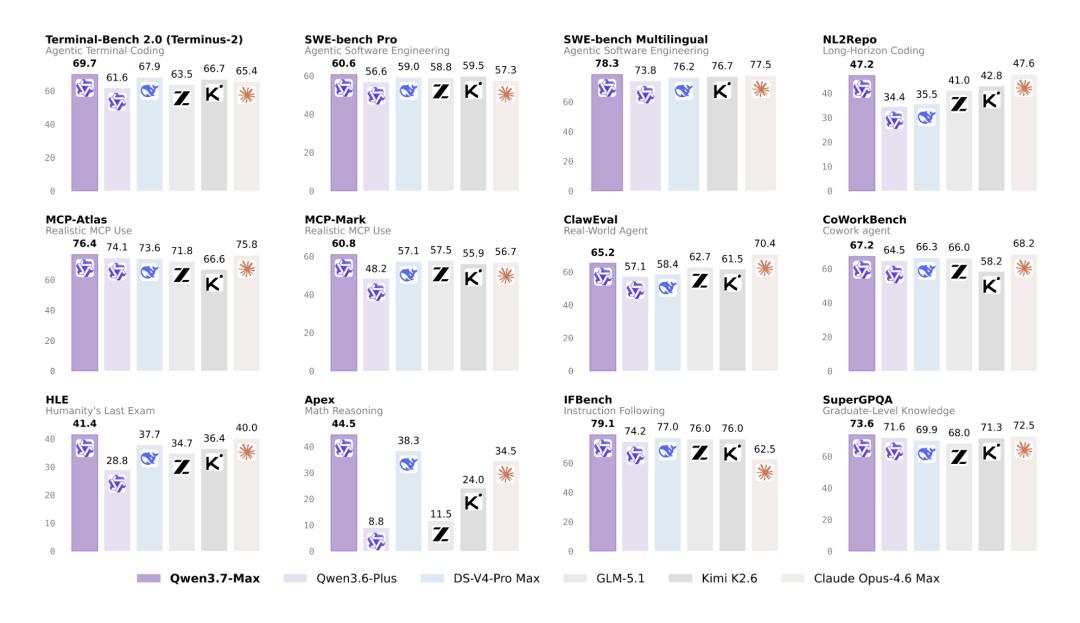
最新一期的全球性大模型榜单由第三方机构发布, Qwen3.7-Max在此次榜单中获得了56.6分, 其排名处于全球第五位,并且在国产模型里位列第一。这样的位次表明国产模型首次成功挤入一线梯队, 将同期在国内面临的对手甩在了身后。榜单的前列长时间被GPT、Claude等系列所占据, 国产模型能够取得这样的成绩, 是一次实实在在的跨越。
对于用户而言, 无需再去羡慕海外的模型, 国内同样能够用上具备顶尖水平的AI产品。这个排名并非徒有虚名, 而是有着能力方面的硬指标, 它在用户体验上能够直接体现出来。
编程智能体能力全面超越
在编程智能体方向之中, Qwen3.7 – Max多项测评所获得的分数, 超越了像GPT以及Claude这类头部模型。此领域属于大模型角逐时竞争最为激烈的赛道, 无论谁的代码能力突出, 谁便能够成功拿下开发者市场。对于程序员而言, 可以借助它来编写复杂函数, 还能够调试代码, 甚至可以生成完整的项目框架。
实际测试当中, Qwen3.7 – Max具备处理多文件项目代码重构的能力, 还能够迅速定位报错缘由。在面对那些需要常常进行代码编写以及维护的开发者而言, 此项能力能够直接使得工作效率得到提升, 进而减少加班时长。
通用智能体实战能力创新高
通用智能体的能力有了大幅度的升级,多项在实景环境下的能力测试取得了国产领域的新高度。所说的实景测试, 考查的并非是答题, 而是实际干活的能力, 比如说, 能否对工具进行调试, 能否执行长链路任务, 能否自行发现并纠正错误。Qwen3.7 – Max在实际开展的任务当中, 展现出相对稳定的表现, 能够达成多步骤的操作。
像让智能体去订机票, 去查天气, 去规划行程, 它能够自动调用相关工具, 顺着顺序去执行,碰到错误还能够自动重试。这样的能力对于那些做自动化办公的企业团队而言十分实用, 对于智能客服的企业团队来讲也非常实用。
推理能力压过全系同级产品

其推理能力, 超越了GPT全系处于相同级别的产品, 还压制住各式各样的国产模型。这一产品在指令遵循、多语言理解以及翻译方面上, 同时刷新了自己的纪录。针对做数学题、逻辑推理、进行法律条条文目的分析, Qwen3.7 – Max这款工具都能够给出确切精准的答案。
即使是处于复杂问题场景之中, 像是撰写论文这个行为, 又或者是开展数据分析工作, 再还包括进行商业决策支持这些情况, 用户在此时能够直接去依靠它所具备的推理能力。以往那些必须经过多步人工推理才能够攻克的难题, 现如今仅仅通过一次对话便可以将其解决掉, 进而节省了大量的时间。
免费开放拉高行业竞争维度
今年下半年, 国内大模型集体步入卷免费的阶段, 百度将开源价格压低至极限, 字节豆包凭借免费策略冲击日活数量, 月之暗面、智谱同样在对免费额度作出调整, 阿里此次直接把旗舰模型于千问APP作免费开放之举, 是将竞争维度由考量谁更具价格优势转向评判谁的免费版本更为出色。
对于普通用户而言, 能够免费使用处于全球第五位置的模型, 门槛差不多近乎为零。对于开发者来讲, Qwen系列始终秉持走开源路线这件事, 旗舰模型可免费使用这一情况也意味着上层应用的成本结构将会被重新进行计算。
零门槛体验旗舰级能力
刷新千问 APP 直至 6.9.7 及往上版本, 点击底部之 Qwen3.7 – Max 入场通道便可用。计算机终端与网页终端于模型挑选栏下拉更替, 操控路径简易。编写代码之人能够借其与 GPT 开展对照检测, 瞧瞧于实际项目里哪一个更称手。
实施智能体运用的团队, 国产崭新的实景本领所意味着的是, 往昔仅能借助海外模型运行的繁杂任务链, 如今增添了一个本土的选择。一般用户将APP予以更新便可进行体验, 不存在任何缘由错过。轻便化的接入途径, 搭配上旗舰级的模型能力, 才是此次升级确切的完整拼图。
你打算运用Qwen3.7-Max来开展写代码的动作, 还是运用它去充当智能体? 要是你有这方面的使用体验, 欢迎在评论区域分享出来, 还请点赞并且转发给有需要的友人!



