美团开源万亿参数大模型LongCat-2.0,国产算力突破
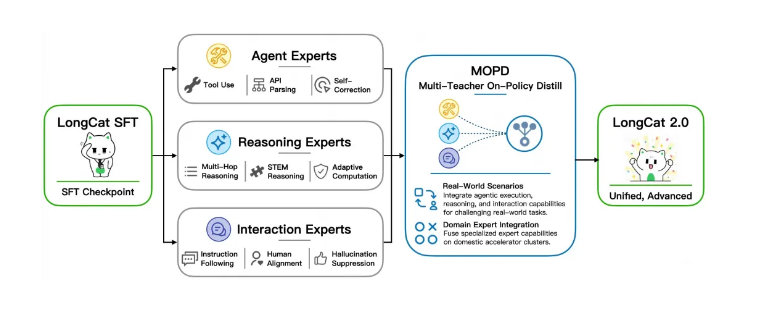
LongCat-2.0。总参数(平均激活约48B,动态范围33B~超长上下文。模型之一。该模型的推出标志着国产算力在大规模集群训练上的重大突破。tokens。的闭环落地与应用重构。
五万卡国产算力集群完成训练
美团于6月30日正式开源了万亿参数大模型 -2.0, 此为业界首个在五万卡国产算力集群上达成全流程训练与推理的模型, 项目自2023年启动, 龙猫团队花费三年时间, 攻克了算子适配跟通信优化等难题, 达成了国产算力在大规模集群训练上的重大突破, 该模型总参数达1.6T, 平均激活约48B, 动态范围在33B到56B之间, 原生支持1M超长上下文。

自研技术降低故障率七成以上
团队借助自主研发的确定性算子以及弹性恢复机制, 极大程度提升了训练稳定性, 其中月均日故障率下降幅度超过70%, 稳态日吞吐量超过1T, 这些技术突破针对分布式训练里常见的硬件故障和通信瓶颈问题加以解决, 使得大规模集群能够持续且高效地运行, 龙猫团队在基础难题方面所进行的攻关, 为国产算力于大模型领域的应用铺平了道路。
稀疏注意力机制降低长文本计算量
这一模型架构, 是围绕真实智能体任务而展开的, 它引入了稀疏注意力机制, 也就是LSA, 把长文本的计算量降低到了线性级。这表示在对待百万级上下文的时候, 计算资源的消耗, 不会再依据文本长度呈指数增长。与此同时,该模型运用了零计算专家机制, 以及MOPD多专家融合架构, 达成了Token级的动态激活, 确保只在有需要的时候才去调用计算资源, 从而大幅提高了推理效率。
编程评测超越GPT-5.5和Opus4.6
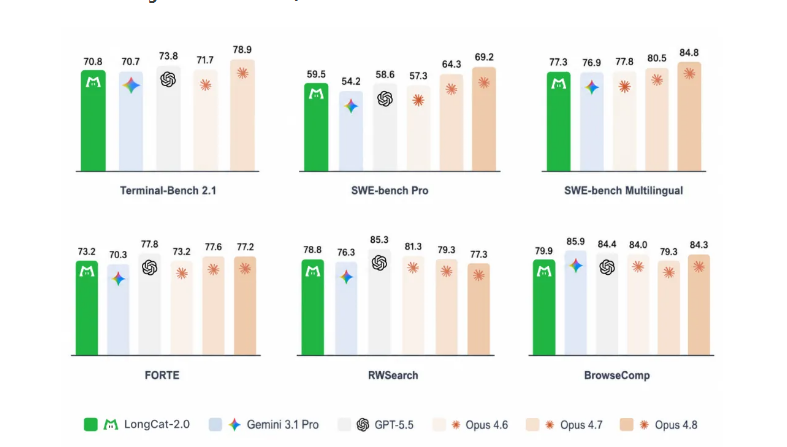
在权威编程评测SWE-bench Pro里, -2.0的表现 surpassedd GPT-5.5和Opus4.6。该模型在代码理解这一场景里表现出色, 在数学推理这一场景中表现出色, 在长程检索所涉及的复杂办公场景中表现优异。这些能力源自针对真实任务的优化之举, 使得模型更契合企业级应用的需求。预览版在平台发布之后, 月调用量已身处全球前三行列, 成为全球范围内备受开发者青睐的Agent模型之一。
超长上下文支持复杂办公场景
让模型能够一次性处理整本书或者大型代码库的, 是原生支持的1M超长上下文, 这对于代码审查、文档分析、法律合同审查等需要全局理解的办公任务相当重要, 在不拆分输入的情形下, 开发者能够直接让模型理解完整上下文, 如此大大提升了任务完成的准确性以及效率, 该能力在Code等生态当中表现亮眼。
加速企业级AI Agent落地应用
美团将此模型开源之后, 企业能够直接进行部署并加以使用, 不必要再从最开始去训练大型模型。该模型于代码、数学推理以及长程检索方面所具备的优势, 能够促使智能客服、代码助手、数据分析等Agent应用的闭环得以更快实现落地。企业能够依据-2.0来构建定制化的AI助手, 从而降低开发所需的成本以及时间。在未来, 国产大型模型于产业里的应用将会变得更加广泛。
你可晓得, 万亿参数模型于编程评测里超越GPT – 5.5究竟意味着啥, 欢迎于评论区去分享你自身的看法, 点赞以及转发能促使更多人知晓国产AI的突破!