
DeepSeek联合北大发布DSpark,AI推理速度提升60%-85%,已开源
推理加速框架,旨在解决大语言模型在高并发生产环境中的推理效率瓶颈。对话系统响应偏慢的核心原因之一。但推测解码的实际加速效果受制于两个因素:一是候选生成的质量,二是验证阶段对目标模型计算资源的占用。的设计围绕上述两个瓶颈展开,提出了两项互补机制。
大模型推理慢的老问题
大语言模型在进行文本生成之际, 所采用的是自回归方式, 每一回生成一个全新的token之时, 均需历经一次完完全全的前向传播, 其推理延迟会随着输出长度呈现线性增长的态势。而这正是作为所有AI对话系统响应之所以偏慢的核心缘由所在, 以至于导致用户等待上几秒才能够看到回复已然成为一种常态现象, 从而对使用体验造成了极为严重的影响。
2026年6月27日, 联手北京大学正式推出推理加速框架, 专门用以处理高并发生产环境里的推理效率瓶颈。该框架已在-V4-Flash与-V4-Pro的预览版服务引擎中进行了部署, 相较于此前所采用的单token推测解码基线MTP-1, 在同等吞吐量情形下把单用户生成速度提高了60%至85%。
推测解码的基本原理
一条解决路径由推测解码技术提供, 即先利用一个轻量级小模型飞速生成若干候选token, 接着让完整规模的大模型借助单次并行前向传播予以批量验证。验证阶段具备并行计算的特性, 而且拒绝采样机制把输出分布与原始模型保持一致严格保障, 能够在不损生成质量的状况下提高速度。
但推测解码的实际加速成效受限于两个要素, 其一为候选生成的质量, 其二是验证阶段对目标模型计算资源的占用情况。当前存在的方案, 要么是串行生成致使延迟随着候选长度呈线性增长, 要么是并行生成然而接受率却迅速衰减, 进而造成目标模型计算资源有所浪费。
半自回归架构的创新设计
在候选生成的阶段之时, 采用的是那种半自回归架构呢: 计算之中那个量比较大的与之并行而行的主干网络, 一次性地直接产出全部候选位置的隐藏状态以及基础概率, 随后, 经由一个轻量级且按顺序排列的模块, 逐个逐token地去注入前缀依赖之信息。这样的一种设计, 一方面保留了并行架构所具备的低延迟的优势之处, 另一方面又借助少量的自回归依赖从而提升了生成的质量。
那顺序模块给出了两种达成途径, 一种是单单依靠前一个token的马尔可夫头, 另一种是利用循环状态累加完整前缀信息的RNN头。试验证实, 两层深度的就能在所有测试领域里超出五层的接受长度, 这表明少量自回归依赖的引入在参数效能方面比单纯堆叠并行层更具优势。
硬件感知调度器的核心作用
输出一个置信度分数, 是模型于每个候选位置进行的操作, 即对该token在给定此前所有token均被接受的条件下的存活概率作出预测。在受训阶段完成之后, 团队于验证集上借助逐位置温度缩放来校准置信度, 目的是使其与经验接受率达成对齐。
在此基础之上, 硬件感知前缀调度器把验证长度选择建构成为全局吞吐量最大化的问题 , 它针对一组并发请求以及这些请求各自位置的置信度 , 再结合事先实测的引擎吞吐量曲线 , 为每一个请求动态地判定要验证多么长的候选前缀 , 优先把目标模型的计算资源分配给全局存活概率最高的token。
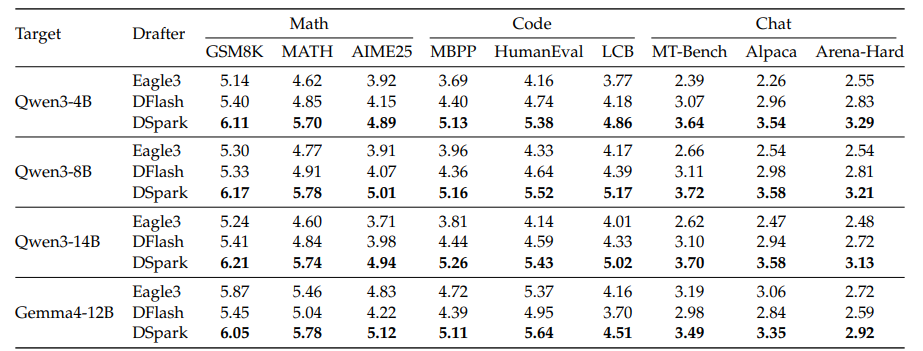
离线与在线测试数据表现
研究团队在进行那个离线基准测试的时候, 选了Qwen3系列以及-12B当作目标模型, 实施对比自回归草稿模型跟并行草稿模型的操作。在数学推理、代码生成还有日常对话这三类任务当中,平均每轮接受长度都比两类基线要好, 位置级条件接受率所做的分析也证实了它的设计上的优势。
于生产部署区段, 草稿模型会同-V4-Flash以及-V4-Pro预览版一块儿实施部署, 并行的主干涵盖三个 MoE 层和滑动窗口注意力。在在线生产环境展开实测期间, -5 与原本的单 token 基线 MTP-1 予以对照, 于 V4-Flash 引擎之上,当系统确保单用户生成速度不少于 80 token/s 的时候, 聚合吞吐量相较于基线提高了 51%。
实际部署效果与局限分析
SLA收紧到120 token/s之际, 单token的基线毗邻运行的边界边缘了, 维持可用并发批处理不作变更的条件下, 达成了标称661%的吞吐量优势。实际吞吐量水平予以配合时, 单用户生成速度得以提高, 提升幅度57%到达85%, 并且调度器显示出负载有自适应能力的验证预算分配情况, 分配能力是关乎验证预算的。
它存在的局限之处在于, 纵使后缀的token最终被调度器给截断了, 然而并行主干仍然需要为所有的请求去生成完整的初始候选块, 如此一来在某种程度上就对资源利用效率形成了限制。不过总体来讲, 这个框架已经在真实的生产环境当中证实了其具备提升大模型推理效率的能力。
你觉得这般推理加速技术能不能完全处理大模型回应迟缓的难题呢, 欢迎于评论区去分享你的见解 , 点赞并收藏此文本让更多人瞧见!