
腾讯混元等推出开源框架,用于评测训练大语言模型规划能力
这是一个旨在评测和训练大语言模型规划能力的可扩展、可验证的数据生成框架。这一框架不仅能够评测模型是否具备规划能力,还可以为模型的规划能力训练提供稳定且可迁移的奖励信号。是腾讯与人大高瓴联合开发的开源框架,旨在评测和训练大语言模型的规划能力。
大模型会聊天但不会做计划 这个短板终于被补上了
大语言模型当下具备写诗的能力, 也拥有编程的本事, 然而一旦碰到诸如安排一周会议、分配项目资源这类需要多步骤、多约束的规划任务时, 常常就问题诸多。腾讯混元团队同中国人民大学联合开源的PlanGen框架, 正是致力于解决这一痛点。它仿佛是一位全能考官, 专门针对大模型在真实场景里的规划能力展开评测与训练, 使得AI不再只停留在理论层面。
覆盖30多种规划任务 拒绝单科刷题
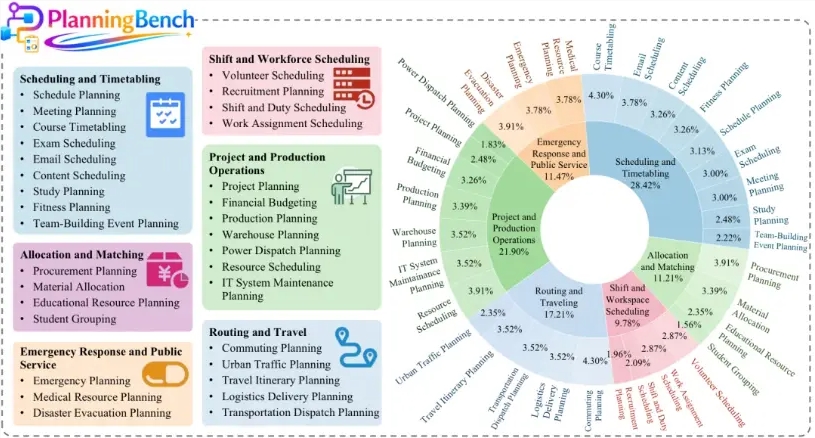
不少模型于特定任务里表现较为良好, 然而一旦更换场景便会失效。PlanGen构造了超30种规划任务类别, 那其中包含日程的排布、资源的分配、人力的排班、路径的调度、生产的运营以及应急的服务这六大实际应用当中的情况。这样的设计致使模型不得不掌握通用的规划逻辑, 并非依靠记忆特定数据来刷分。就像同一个模型既要能够安排快递员的路线, 又要可以规划工厂的排产。
难度控制体系直击真实痛点 不搞字长游戏
以往如果要增大任务难度, 常常是依靠去延长提示该任务的文本, 进而使得模型能够在超长的上下文环境当中去寻觅答案。PlanGen的难点控制体系相对更为聪慧, 它会对任务结构予以拆解, 对约束层级加以考量, 也会顾念资源紧张的程度, 从而让生成的数据围绕实际决策瓶颈用以设置相应挑战。举例而言, 在资源分配任务方面, 并非是单纯地去增加物品的数量, 而是呈现出致使多个需求同时去争抢有限资源的情形, 以此来考验模型的优先级判断。
每条数据自带验证器 合规与成功双把关
传统的评测常常只是去看局部是不是正确, 比如说在计划里前几步要是合理就能够得分。PlanGen给每一条数据实例都配备了验证器, 它会同时检查局部的合规情况与全局的成功状况。这就有一种情况, 就是一个看上去每一步都正确, 然而整体没办法去执行的计划, 会被直接判定为失败。在2025年的某次内部测试当中, 这个机制准确地识别出了模型输出里23%的“虚假成功案例”。
可验证训练信号 让模型越练越聪明
PlanGen给出稳定的、能够被验证的奖励信号, 这就如同给模型配备了会自动批改的老师, 模型每生成一个计划, 系统马上反馈何处违反了约束, 何处路径是最优的, 基于这些信号开展强化训练后, 模型在未曾见过的规划基准上表现提升显著, 据团队测试, 经过PlanGen训练的模型在通用任务上的成功率平均提升31%, 这证明了学习信号具有通用性。
真实场景驱动闭环 从生成到迁移一站解决
其框架构成了一个完备的闭环, 从实际场景中提炼出任务类别并衍生出带有验证的数据后, 使用此类数据来训练模型, 接着转移至新任务去证实效果。在2026年初的时候, 众多企业已将上述这一框架应用于供应链调度以及客服排班系统之中。在未来, 凭借PlanGen的训练方式很有可能会演变成大模型规划能力的基础部件, 如同当下的指令微调那般普遍。
对于大模型而言, 你设想一下哪种规划能力最为亟需提升, 是那种能够助力你去安排旅行路线的能力吗, 又或者是那种可以优化公司排班情况的能力, 在此诚挚欢迎于评论区踊跃分享你个人真情实意确切的需求, 同时烦请点赞以及转发, 以此达到让更多人得以看到AI规划方面最新突破进展的目的。
