新闻资讯
DeepSeek公布最新文档识别模型DeepSeek-OCR 2,有啥新突破?
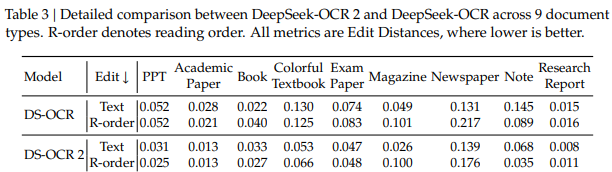
这项技术突破源于对传统视觉语言模型处理方式的重新思考,旨在让机器更贴近人类的视觉阅读逻辑。会被送入后续的解码器,用于生成识别结果。仍沿用了前代模型的编解码框架。进行语义建模和顺序重组,最后交由一个基于混合专家架构(MoE)的语言模型解码。0.057,表明新模型能够更合理地理解文档内容结构。
近些年来,光学字符识别技术所取得的每一回具有实质意义的进展,都受到了极大的关注,这是由于它对地影响着数量诸多的纸质文档进行数字化处理时的效率以及准确性。就在上个月期间,有一个从事研究的团队公布了其新一代文档识别模型的最新研究成果。
核心升级的出发点
当传统的,用于文档识别的模型在对图像展开处理之际,一般会用到固定的,依照栅格扫描的顺序,像是把一张纸张按照自从上到下之后,又往从左到右,这般机械地切割成为大小不大的块状。此一种方式忽略掉了人类在进行阅读这个行为之时的一个相当重要的特性:我们的视线会依据内容的,具备之中那种,逻辑关系进行跳跃,举例来说把,会第一步,对标题予以查看,接着再度观察图表,最终才去阅读正文。
在朝向复杂版式,像是有着包含侧边栏、多栏文本或者嵌套表格的学术论文时,这种以固定顺序的处理方式,极易引发理解偏差,致使模型有可能没法正确拼接不同栏目的内容,进而造成识别出的文字顺序处于混乱状态,最终使得原有的语义逻辑丧失。
引入动态视觉排序
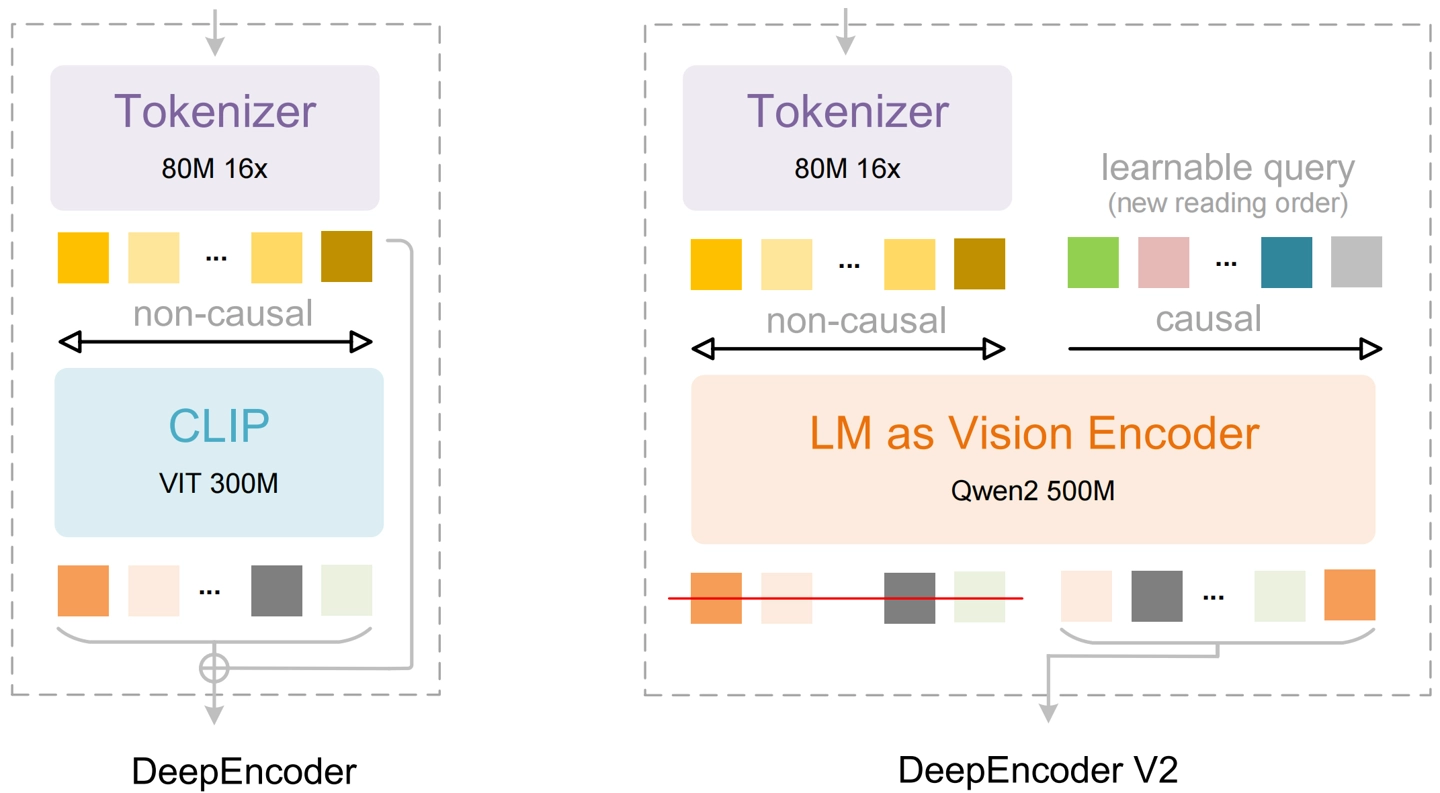
对于解决上述问题而言,新模型的核心创新之处在于其视觉编码器,团队设计了一种名为V2的新型结构,该结构能够模拟人类的阅读逻辑,在处理视觉信息的时候动态调整顺序,仿佛是给机器安装了一个“智能视线导引器”。
此编码器之内含有两种注意力机制,其一负责全局方面获取感知,能够快速地扫描整幅图像,其二如同人类从事阅读一般,依据语义因果上的顺序,一步步聚焦至下一个最为相关的视觉区域,借由这样的方式,模型于识别文字以前,就已产生了对于文档结构更为合理的理解。
技术架构的具体实现
于整体设计方面,此模型依旧运用了编码器 - 解码器的经典架构。编码器先是把输入的文档图像转变为一系列视觉标记,接着经由新型的V2编码器针对这些标记开展智能排序以及语义建模,最终把处理妥当的信息传送给解码器用以生成文本。
请注意,解码器选取混合专家架构,此设计使模型能按当下要处理的内容类别,灵动调用最拿手的子模块,像处理数学公式与识别普通段落时,能够激活各异的“专家”,进而在不明显增添计算负担的情形下,提高整体处理的精准度与效率。
性能的量化评估
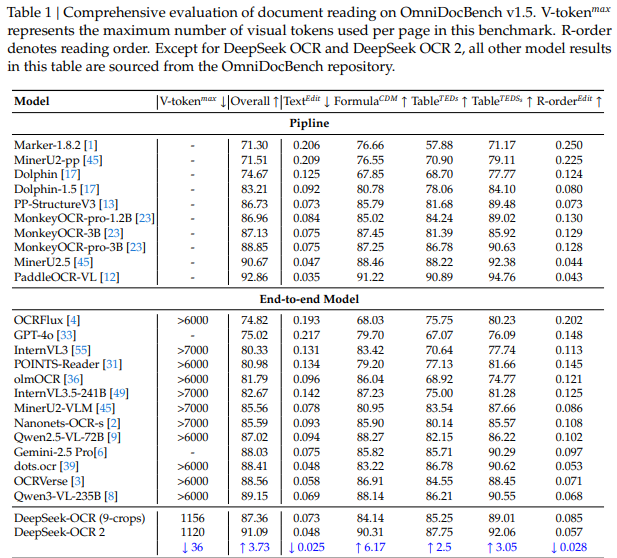
要去验证新模型实际呈现出来的效果,研究团队在一个被称作v1.5的综合性基准之上开展了测试,这个测试所涉及的集合涵盖着大量的中文和英文的实际类型的文档样本,像杂志、报告以及学术论文这样的,评估所涉及的维度包含了文字识别所具备的准确率、公式解析所拥有的能力、表格结构进行还原的程度以及关键的阅读当中顺序的确切性。
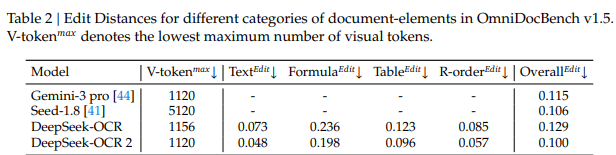
测试得出的数据表明,新模型的综合得分实现了91.09%,相较于前代模型提高了将近4个百分点。特别是在用以衡量阅读顺序准确性的编辑距离指标方面,数值由0.085降低到了0.057,这表明模型输出文本的逻辑顺序更加贴近人类阅读的实际顺序,错误的部分变得更少了。
实际应用的可靠性
团体除了进行实验室基准测试之外,还搜集了源自生产环境的真实数据用以评定模型稳定性,数据表明,于处理在线用户上传的日志图像之际,内容重复率由6.25%下降到了4.17%,在处理批量PDF文档的情况下,重复率同样从3.69%降低至2.88%。
这些重复率指标出现下降情况,这代表着模型由于误判版面结构故而重复输出相同内容这种错误明显变少。在需要处理总量极其庞大文档的金融领域、法律领域或者档案数字化这些场景中来看,此类情况意味着可以获得更高的产出质量,并且还能有更少的人工校对成本,这样的种种情况具有的实用价值是非常显著的。
对未来发展的启示
这项技术实现突破,其重要意义并非仅仅局限于让一个模型的性能指标得以提升,它更显著地意味着一种研究范式发生了转变,即从以往简单地使机器被动去接纳固定了的图像处理流程,转而变为引导机器积极主动地剖析并重新构建文档所蕴含的内在逻辑框架,这一转变为后续针对更为复杂、呈现非结构化特点的视觉信息开展处理活动提供了全新的思路。
数字化进程不断深入,我们要处理的文档类型会越发多样,从古老陈旧的书籍到设计方面的图纸,挑战源源不断。那种能够“理解”而非只是“看见”的模型,也许是把混乱无序的视觉信息转变为有序、可以使用的知识的关键一步。
您试想,这般具备模拟人类阅读逻辑功能的OCR技术,最初会于哪一种行业或者场景当中冒出颠覆性的应用价值呀?踊跃于评论区域递上你的看法,要是觉着此文存有帮助,同样请点赞以作支持哦。