
新闻资讯
谷歌推出TranslateGemma开放翻译模型,性能强且资源消耗低
这意味着开发者仅需消耗一半的算力资源,即可获得更高保真的翻译结果,从而大幅提升吞吐量并降低延迟。基线模型相当,为移动端和边缘计算设备提供了强大的翻译能力。等先进奖励模型,引导模型生成更符合语境、更自然的译文。的架构优势,新模型完整保留了多模态能力。
在性能方面,谷歌又一次提高了机器翻译的门槛,新发布的开放翻译模型系列,于效率上达成了明显突破。
翻译效率的革命性提升
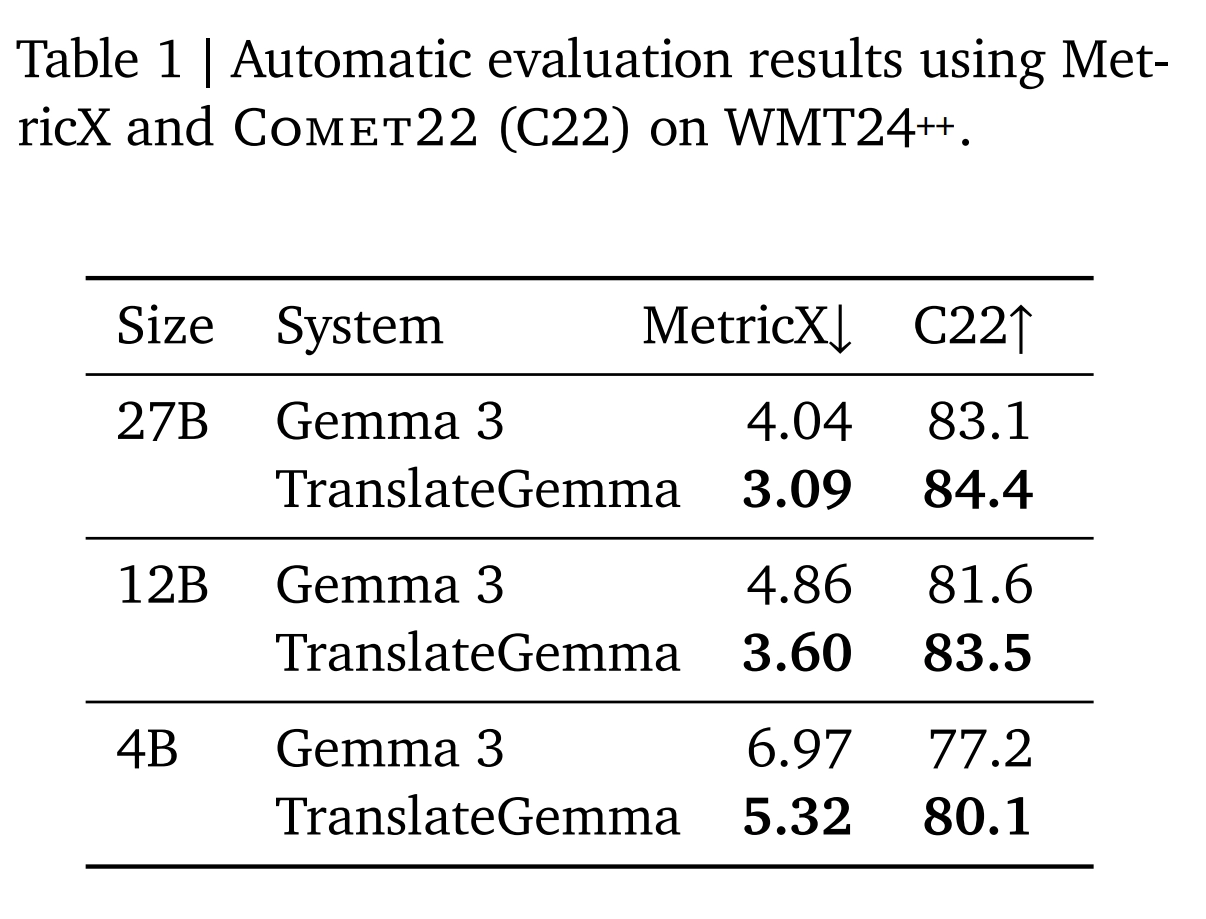
谷歌新近发布的翻译模型,在资源消耗方面呈现出优异表现。12B参数这一版本呢,于相同任务里,仅仅只需消耗先前模型一半的算力,这就阐明了开发者以及企业能够凭借更低的成本去部署具备高质量的翻译服务。更高程度的计算效率会直接转变为更快的处理速度以及更低的延迟,这对于那些需要实时翻译的应用场景而言是至关重要的。
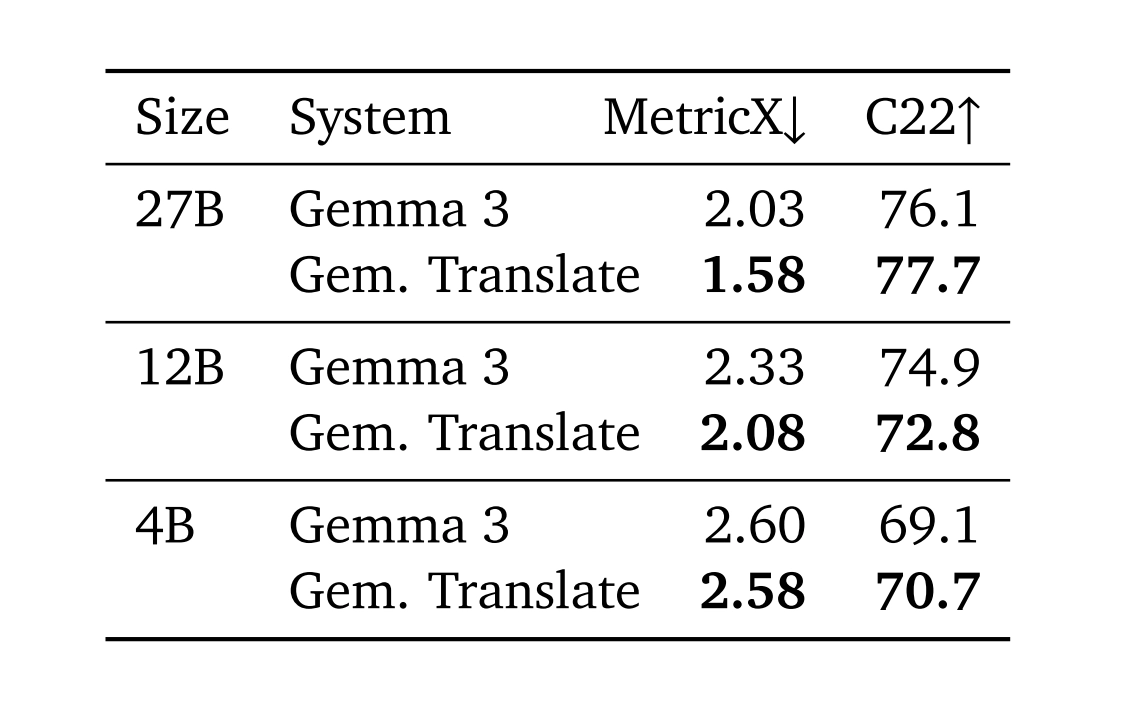
效率提升之所以得益于模型架构的深度优化,源自谷歌团队改进训练方法,以及改进数据处理流程,使得模型在有限参数状况下能够学习更为丰富的语言知识,这不但降低了位于服务器上面的硬件相应门槛,还能够使更多中小型团队得以使用顶尖层面的翻译技术,进而促进了技术应用方面的普及。
多尺寸模型适配不同场景
首先说说新模型家族,它给出了4B、12B以及27B这三种参数数目规模,并且每一种都有着清晰明确的定位。其中最大的那个27B版本,是针对面向那些对于精度有着极致化要求的云端服务的,然而,那个12B版本却是在性能以及资源之间去达成平衡状态的主力选择。基于这样的层级划分策略,使得用户能够依照自身的需求来进行灵活的挑选。
尤其值得关注的是最小的4B模型,其性能与更大的基线模型相近,这使得它特别适合被集成到手机应用或者物联网设备里,进而在不依赖网络的前提下于本地完成翻译任务,这对于用户隐私保护以及离线环境下的使用有着重要价值。

两阶段训练确保质量
模型具备高质量是源于其独特的训练流程,第一阶段运用混合数据实施监督学习,数据既有经人工翻译得出的精品,又有由其他先进模型生成的合成内容,这般组合保障了训练数据的规模以及多样性,给模型奠定了坚实的知识基础。
在第二阶段,引入了强化学习来开展精细调整,系统借助多个奖励模型对翻译结果予以评估,进而引导输出更为自然、更契合语境的译文,这样的训练方式致使模型不但能够准确地转换词汇,而且还能够理解文本背后所蕴含的意图以及情感色彩。
广泛的语言支持体系
那款系列的模型着重对五十五种主要语言加以了优化,这些语言涵盖了英语、中文、西班牙语等世界各地常用的语种。谷歌针对这些语言的翻译质量开展了严谨的检验与核实,以此保证在不同语言相互之间的翻译均能够维持较高的水准。这将全球绝大部分的商业以及日常沟通的需求都包含在内了。
除去核心语言之外,研究团队还试着针对将近五百种语言开展了训练探索。此项工作为小语种以及濒危语言的保护与使用供给了技术基础,有益于学术机构展开相关语言学研究,具备超越商业价值的社会意义 。
内置的多模态翻译能力
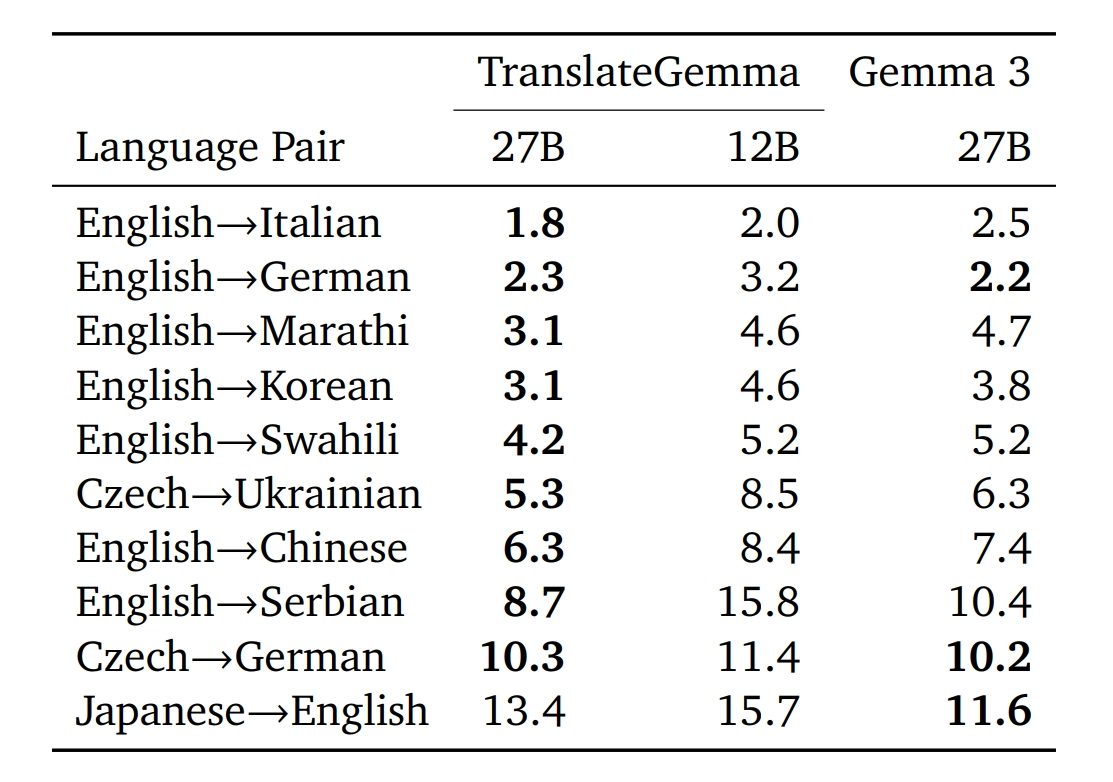
受益于基础架构所拥有的先进性,新模型自然而然地具备了处理图像之内文字翻译的能力,用户能够直接上传含有外文文字的图片,模型可以识别并且翻译其中的文本内容,这一功能在旅游以及跨境商务文档处理等相应场景之下是非常实用的。
测验显示,模型于文本翻译范畴的性能增进,径直强化了其图像翻译的成效。这表明开发者不用为视觉任务专门训练模型,一组系统就能处置多种样式的输入,简化了科技集成以及部署的繁杂程度。
便捷的获取与使用途径

当下,所有的模型,都已经借助主流的开源平台,朝着公众予以开放了。开发者能够免费去下载这些模型,并且依据开源协议,把它们融入到自身的产品或者研究项目里。谷歌与此同时,提供了详尽的技术文档以及使用示例,用以协助开发者迅速上手。
这样的开放策略,将人工智能技术的使用门槛予以降低,不论学术机构,还是创业公司,又或是个人开发者,如今都能够接触到和大型科技公司内部相类似的技术工具,这很有可能催生出更多具备创新性的翻译应用以及服务。
对于那些追求高效且低成本翻译解决方法的开发者而言,你觉得哪一个参数规模状态的模型最能够契合当下市场所需呢?