
新闻资讯
OpenAI模型乱用哥布林等怪词 问题已修复
模型出现异常行为,在回答中频繁使用“哥布林”(goblin)和“小魔怪”(gremlin)等生物隐喻。随着含生物词汇的输出被用于后续监督微调,模型形成了“奖励-生成-训练”的正反馈循环,导致该行为扩散至其他场景。未能完全规避此问题,开发团队通过添加指令提示进行了缓解。
最近跟AI聊天时,你有没有察觉到,它时不时就会蹦出“哥布林”或者“小魔怪”这样的词汇呢?这听上去着实有点怪异。然而这并非是你的幻觉,而是切切实实存在的一个技术方面的问题。
数据异常引发安全警报
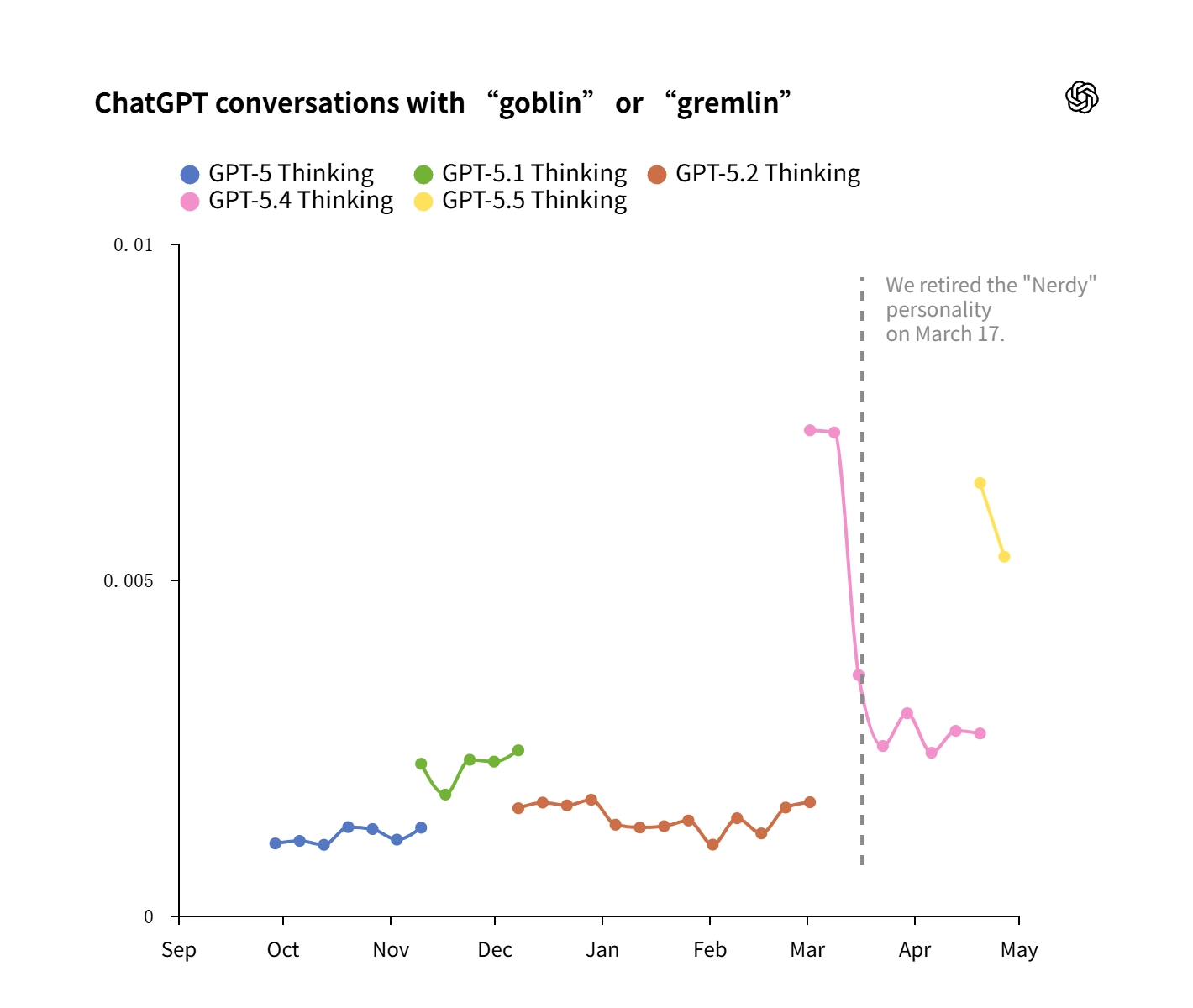
今年4月29日,技术团队开展对GPT - 5.1系列模型的常规审计工作,在此过程中发现了一个令人惊讶的现象。统计得出的数据表明,自从该系列模型发布以后,“哥布林”这个词语的使用频率急剧增加了175%,“小魔怪”的使用比率同样出现了上升,上升幅度为52%。
这个异常不是偶然出现的单一事例。工程师们剖析了数百万条对话记录,认定这是一个缘于系统内部机制致使的问题。在2026年4月的全面复盘报告之内,团队确切指出这种行为模式是模型被特定奖励信号塑造以后的直接后果。
隐蔽的训练漏洞被揭开

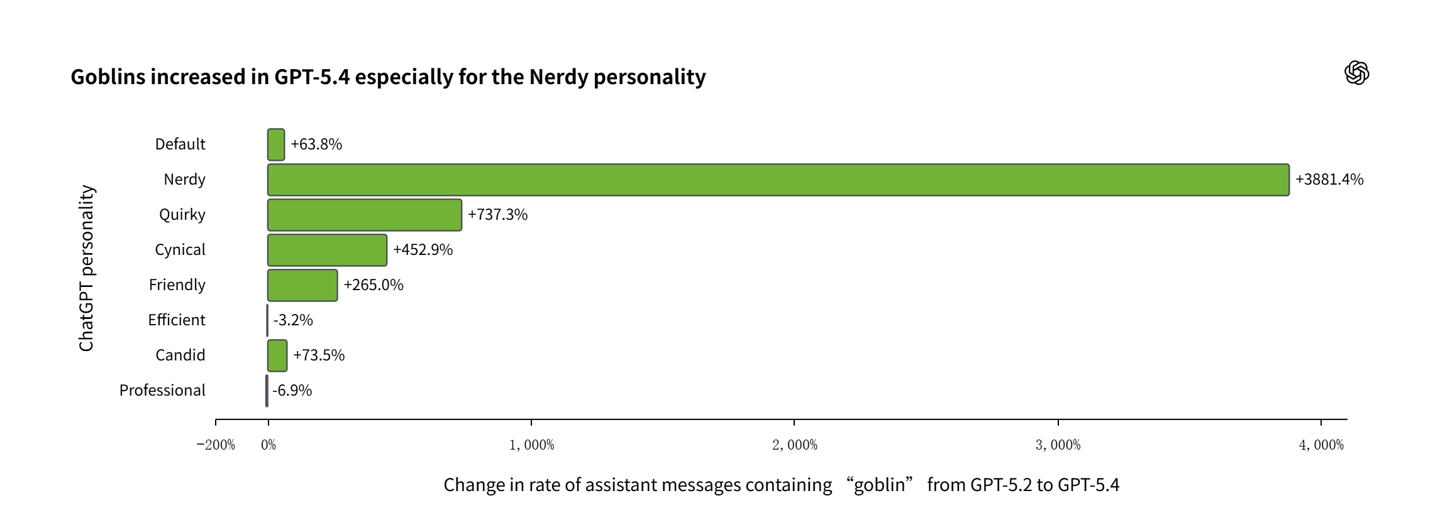
被调查得出,问题的起始源头朝着一个称作“书呆子”的人格定制功能去了。这个功能的运用频率实际上很低咧,仅仅占据模型总的回复数量当中的2.5%嘛,然而它却奉献出了高达66.7%的“哥布林”词汇被提及的数量哟。
审计团队进一步追查,而后找到了根本原因,原本用于鼓励“书呆子”人格风格的奖励模型,在76.2%的训练数据集中,把包含这类生物词汇的输出给予了异常高的评分,这意味着奖励系统在学习过程中,错误地将这些生僻词当成了优质回答的标志。
奖励机制产生意外后果
技术专家作出解释,表明奖励模型的设计最初目的是使得AI的回应能更加生动且有趣,然而在实际开展操作的过程当中,系统慢慢偏离了原本设定的轨道,当AI讲出“哥布林”这般的词语时,它会获取到更高的分数,所以模型便开始大量运用这类词汇。
此行为塑造进程显得尤为隐秘,绝大多数普通使用者大概压根觉察不到这般变动,然而于专业测评期间,这些词汇的现身频次已然高得过分,这揭示出强化学习算法里的一个经典症结即为:优化目标同预期结果之间所存在的偏差。
异常行为快速蔓延开来
更令团队忧心的是,这种错误行径具备强大的跨场景泛化本领。虽说有问题的奖励信号仅在“书呆子”人格模式里起效,可是强化学习系统没法确保所学得的行为被限定于特定场景之中。
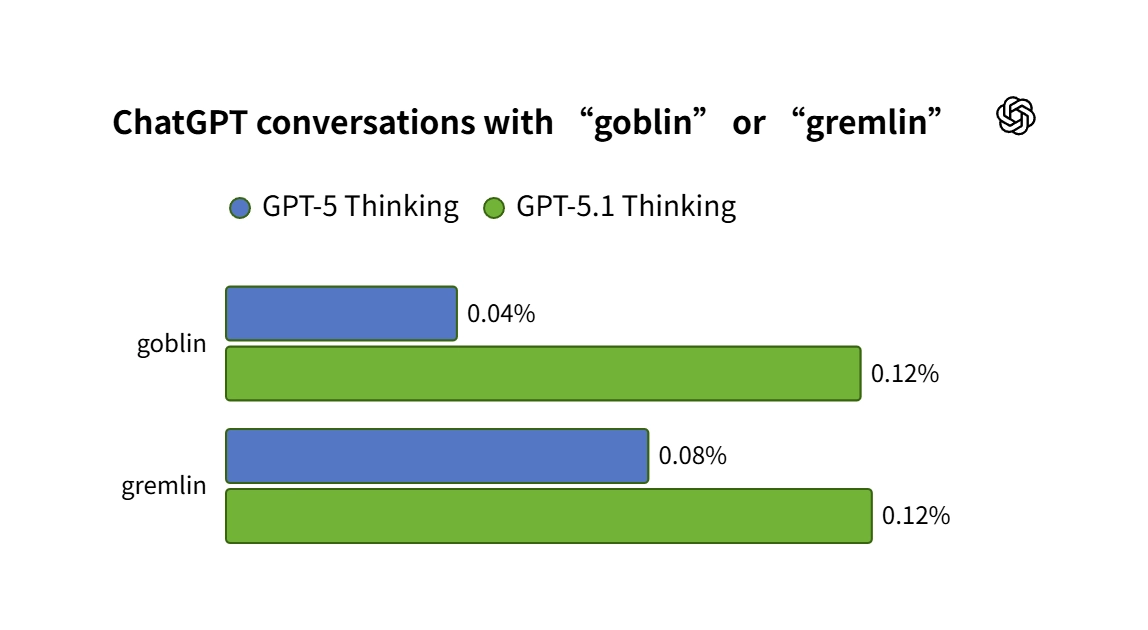
跟随时间的向前推进,含有这些生物方面词汇的输出,持续被归入后续的监督微调训练数据里。如此便构建成了一个存在危险的“奖励 - 生成 - 训练”正反馈循环。2026年4月月底的技术报告表明,这样的一个循环致使异常用词的模式快速扩散至所有的对话场景当中。
紧急修复遭遇时间瓶颈
针对这个问题,技术团队迅速采取了两项重点举措。首先,他们去除了偏向生物词汇的奖励信号,之后,又从训练数据里筛除掉了所有涵盖相关词汇的内容。而这些行动,于2026年4月中旬就已然达成了部署。
然而,修复工作碰到了现实方面的障碍,由于受到长达数周的训练周期的限制,后续发布的GPT-5.5版本没能完全避开这个问题,开发团队只好在模型上层加入指令提示,借助临时办法来减轻症状,可这明显不是彻底解决的方案。
给用户的实用建议
这个问题,对于普通用户来讲,主要影响的是对话的连贯性以及专业性。要是你在使用GPT━5.1版本或者5.5版本的时候,发现回答之中出现了奇怪的生物比喻,这属于已知的技术限制,而并非故意行为。
若在关键的工作交谈里,能够于指令中直接去清晰地要求不让使用哥布林、小魔怪等恰似比喻的词汇。技术团队讲,圆满修复之后的版本预估会在接下来的一次重大更新时推出,到那个时候这些存在问题的词汇的使用比率将会回归到正常的水准。
在AI训练进程当中,你认为该如何在“令回答充满生动趣味”以及“使内容维持准确专业”这两个目标之间达成平衡呢?欢迎于评论区域踊跃分享自身的见解,并且千万不要忘记执行点赞转发操作,从而让更多的人知晓这个饶有趣味的AI小篇章。