
新闻资讯
阿里千问推Qwen-Scope,可解释模型行为
系列模型训练所得的可解释性模块。推理:模型行为的分析与可控的结果对模型表示做了各个方向的解析和归纳,所以它可以用来作为数据处理工具,在数据分类和数据合成上均可提供数据处理思路。可解释性,不仅是事后分析的工具,也可以是驱动模型进化的核心引擎之一。
阿里千问于4月30日推出的Qwen-Scope工具,可让开发者看清模型内部的特征表达,进而更精准地控制并优化模型行为,它正是解决了没人能完全看懂AI大模型这个如同智能黑箱般的内部运作方式所带来的痛点。
什么是Qwen-Scope可解释性模块
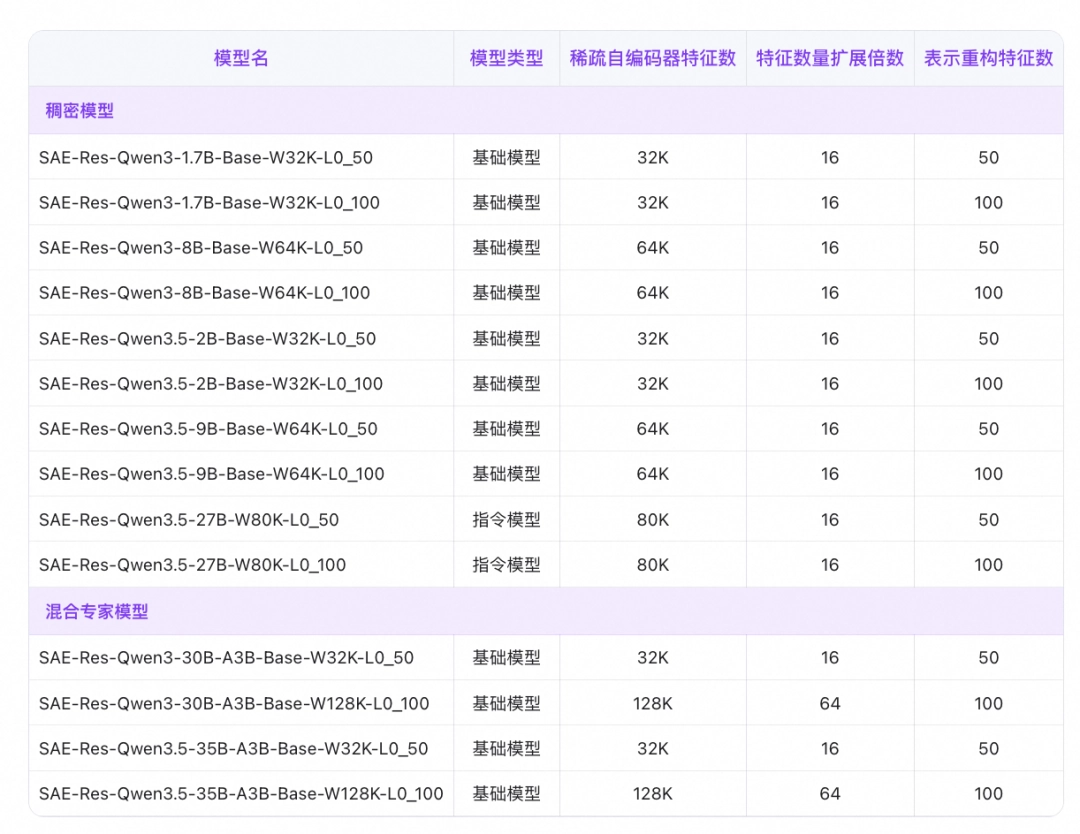
Qwen - Scope是由阿里千问团队所开发的一个模型分析工具,研究团队于Qwen模型的隐藏层当中插入了稀疏自编码器,借助施加稀疏性约束,从而自动提取出高度解耦、低冗余且有着可解释性的隐藏空间特征,这个模块涵盖了Qwen3以及Qwen3.5系列的7个大模型,其中包含稠密模型及混合专家模型,一共有14组稀疏自编码器权重。
阿里团队为使特征分布更为广泛、语义含义更为强烈,从对应模型的预训练数据里采样了规模为0.5B词元的数据来进行训练。目前开发者能够借助此工具,深入剖析Qwen系列模型的内部运作机制,而不只是查看最终的输出结果。
推理结果定向控制
于实际应用里,Qwen - Scope最为直接的价值展现于推理控制方面。传统的AI模型控制得给出明晰的自然语言指示;比如,有着“请用正式语气回复”这样的指令。然而使用Qwen - Scope时,开发者能够直接操控模型内部特征的激活,达成对推理结果的定向更改。
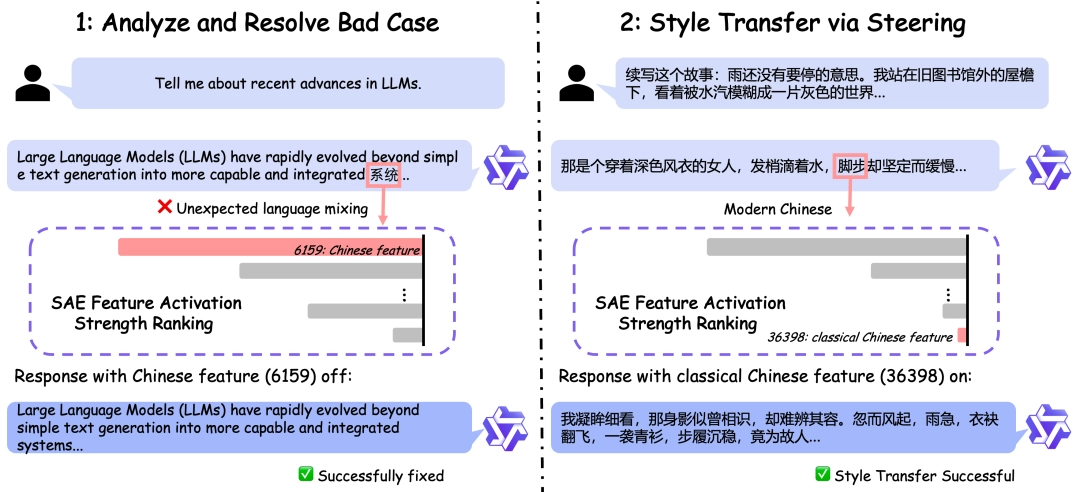
比方说,你要是希望那模型变换回复所用的语言,去调整表达的风格,又或者是更改所提及的实体名称,均可借助调节特定特征得以达成。这般的控制方式更为精细且高效,无需反复对提示词进行修改。对于从事AI应用开发的企业来讲,这意味着能够更为稳健地获取契合预期的输出结果。
数据分类处理新思路
Qwen - Scope于数据处理范畴同样彰显出强大之能力,在毒性数据分类情境之下,开发者能够依据少量种子数据,剖析毒性样本于SAE特征上的激活模式,随后筛选出与毒性高度相关之特征用以分类,整个进程无需额外训练分类器,极大程度降低了标注以及训练成本。
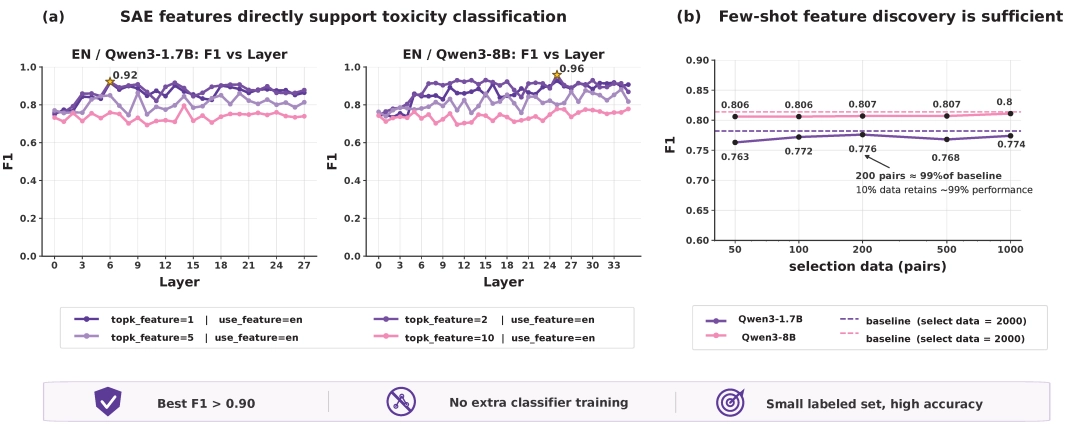
哪怕仅仅依靠少量起初的数据,这一套方法也能够获取较高的分类准确程度。这表明着中小型的开发团队也能够在不拥有大规模标注数据的情形下,达成高质量的数据过滤工作。与此同时,在数据合成的场景当中,Qwen - Scope能够协助识别已经存在的数据里激活次数少甚至是没有激活的毒性文本特点,并朝着特定方向合成补充样本,使得训练数据的能效比提高大约15倍。
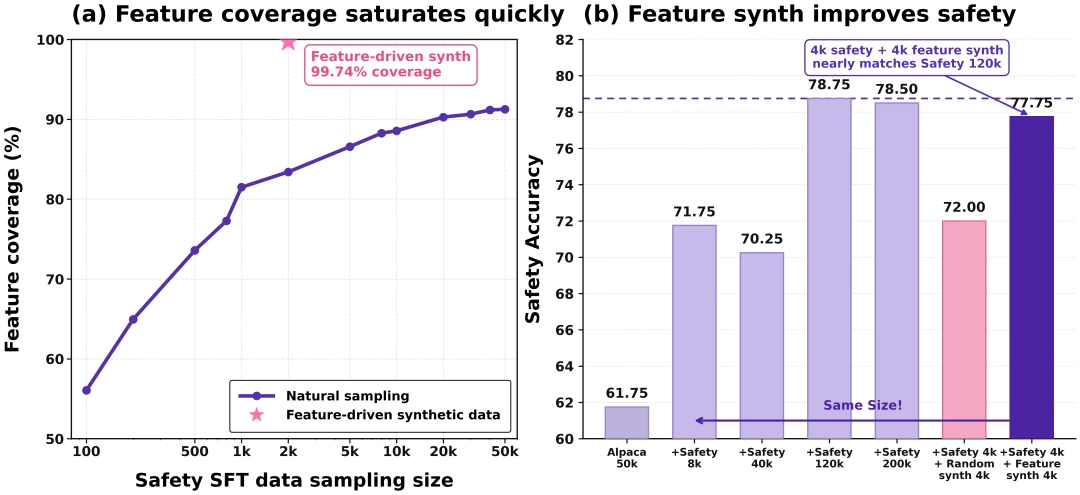
模型训练定向优化技巧
于模型训练阶段之时,Qwen - Scope的特征分析功能同样具备实用性。当开发者察觉到模型存有语言混用情形,像是英文回复里异常地出现中文词汇之际,能够借助此工具寻找到异常激活特征。在监督微调阶段当中,可以针对这些异常特征去设计专门的损失函数,以此引导模型减低问题出现的频率。
另一个典型应用,是解决重复生成问题,这是一种低频现象,它很难在常规的强化学习阶段被采样到,通过Qwen - Scope,开发者能够控制相应特征,提高采样出异常回复的频率,增加学习奖励密度,如此一来,模型便能够在强化学习阶段充分优化这一问题,而无需被动等待问题自然出现。
评测集覆盖度分析
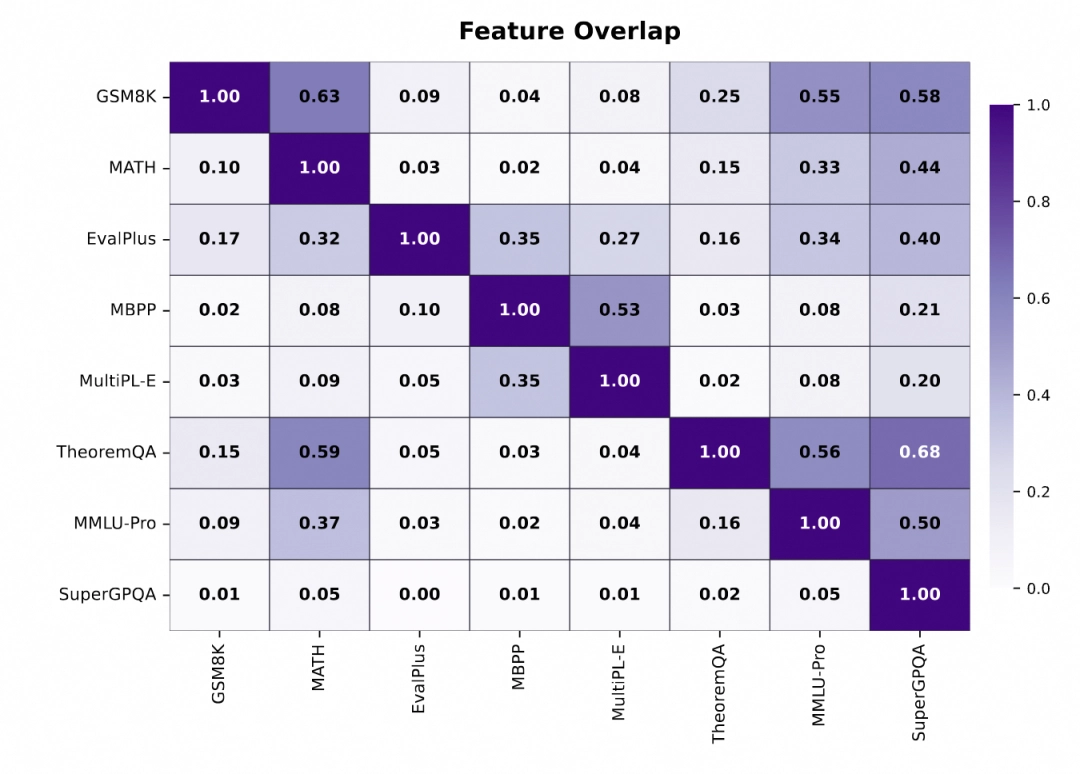
进行大模型能力评估,是项愈发复杂的任务。现在,待评估的能力以及维度日益增多,评测样本规模同样越来越大。哪些评测集存在着冗余情况,哪些领域覆盖不够充分,这成了开发期间的关键问题。Qwen - Scope能够助力分析测试集的特征覆盖程度,判定不同评测集之间评测冗余的程度。
研究团队发觉,部分常常使用的评测集,在其激活的特征方面,存在相互覆盖的关系,致使一些评测集遭受重复评估的干扰,其实用意义相对比较小。借助这种分析方式,开发者能够挑选出覆盖度更高、评测成本更低的测试样本以及评测集,避免在重复且无用处的评测上浪费算力。
可解释性驱动模型进化
Qwen - Scope并非仅仅是用于事后分析的工具,它的真正价值在于能够驱动模型进行进化,这个工具可把复杂的参数运算转化成人类能够理解的概念与规律,使得开发者不但能够“看懂”模型,而且更能“改进”模型,实践已经证明,在推理阶段、评估阶段、数据阶段、训练等各个阶段,它都能够提供优化思路以及指导方向。
已经在魔搭社区开放了Qwen-Scope使用入口的是阿里千问团队,随着越来越多开发者参与进来,这个工具有望在更多场景里发挥作用,可解释性技术正从理论研究迈向实际应用,成为推动AI模型持续进化的重要引擎。
瞧见这儿的时候,你认为对于你于大模型开发或者应用里头起帮助作用最大的可解释性工具是哪种场景呀?欢迎于评论区域分享你的看法,并且也别忘记点赞与转发从而让更多的人知晓这个实用的工具哟。