
新闻资讯
阿里通义实验室开源影视级多模态大模型Fun-CineForge及数据集方法
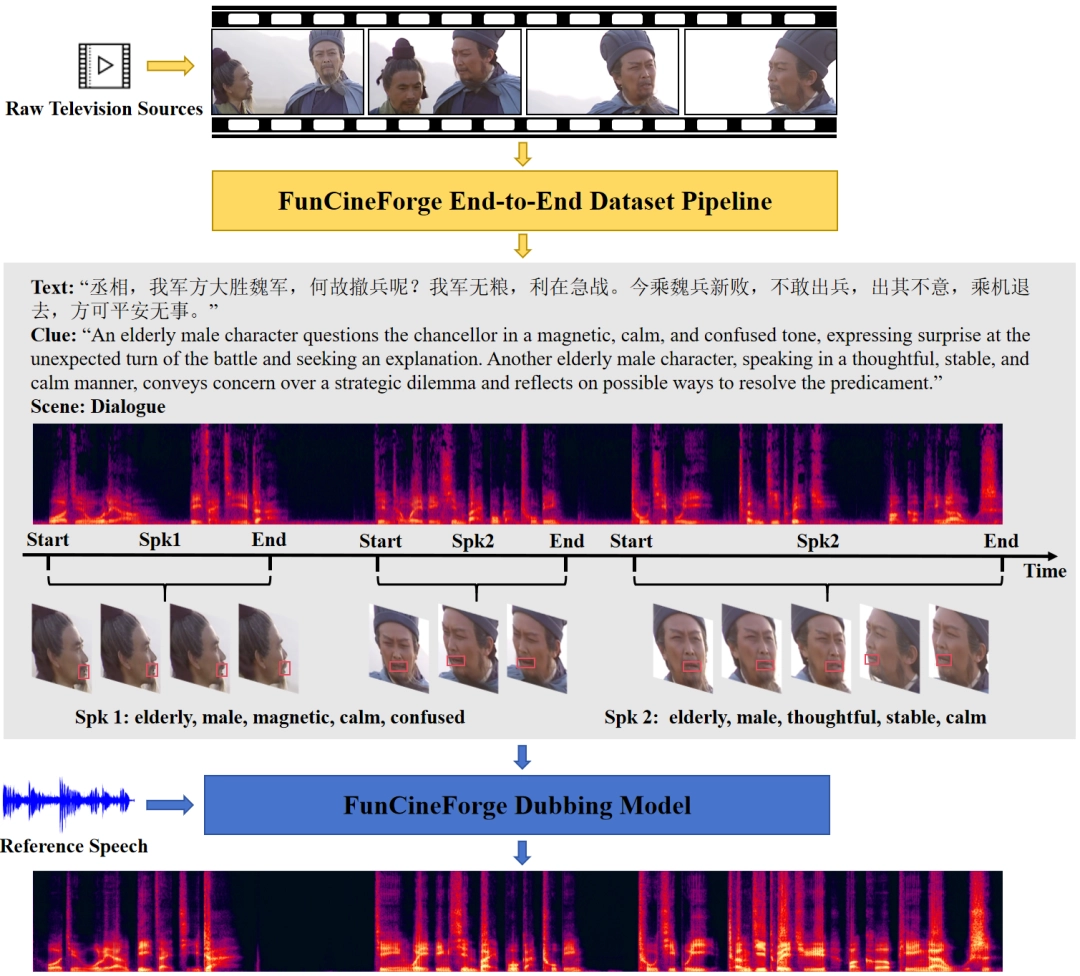
模型侧:面向复杂影视场景的多模态配音大模型数据侧:大规模多模态配音数据集构建流程(CineDub)首先构建了一套自动化的数据集生产流程,可以将原始影视素材转化为结构化多模态数据。最重要的技术创新,是在配音模型中首次引入“时间模态”。配音模型都优于现有开源配音模型,包括:
这次阿里所进行开源的多模态配音模型名为Fun,它直接捅破了影视级AI配音的那层窗户纸,过去AI配音一直被吐槽存在“对不上口型”以及“背景音杂乱”的情况,如今官方宣称它能够同时解决音画同步、多人对话以及面部遮挡这些难题,这就相当于把专业配音的门槛从“百万调音师”的高度拉到了“人人可上手”的程度。
数据瓶颈怎么破
AI用于影视配音时,长期停滞于数据方面。你若想培养一个可分辨出谁在进行话语表达的模型,所需的并非仅仅是音频文本,还必须具备谁张开嘴巴、在何时张开嘴巴,甚至情绪是处于哭泣状态还是欢笑状态等这类信息才行。然而,在市面上所公开的配音数据集当中,要么是由单人在安静环境中录制的新闻播报内容,要么是时长仅有几秒钟的简短片段,总而言之,根本无法涵盖电影里存在的那种多人发生争吵、镜头频繁切换、脸部还被遮挡住的复杂场景。
这次阿里直接公开了数据集的制作方法,他们从350多部中英文影视剧里抠素材,通过人声分离、文本转录、说话人分离这套自动化流程,将原始视频变成结构化数据,特别的是他们运用大模型思维链做双向矫正,降低转录文本和说话人识别的错误率,每个数据样本带有毫秒级时间戳、人脸唇部坐标、角色情感标签,还单独拎出干净人声轨道。
这些数据涵盖了独白,它们包含旁白,也有对话,还有多人场景,其年龄分布被刻意拓展得很宽,性格分布同样如此。基于这样的数据基础,模型才能够学会,在复杂画面里,精准判断“谁在什么时候说什么”。
时间模态是关键创新
传统配音模型存在着一个会带来严重后果的弱点,那就是它们对于“看嘴”有着过度的依赖。一旦画面之中正在说话的人的脸被遮挡住了,或者镜头切换到了其他人身上,又或者光线过于昏暗以至于看不清嘴唇,模型便会一下子陷入不知所措的状态。然而在电影里这种场景是大量存在的,像是有两个人背对着镜头进行交谈,抑或是角色在黑暗的环境当中说话。
这次,Fun引入了“时间模态”,以此来解决这个问题。也就是说,模型不再仅仅关注画面里是否有嘴,而是借由时间轴 信息进行补位。在数据训练期间,对每条语音于视频中出现的起止时间都进行了精确标注。然后,模型学会了这样一件事:即便画面里看不到嘴,只要得知这个时间段有台词,那就得在这个时间区域内发出声音。
使得模型拥有“盲配”能力的是这种设计,实验数据对效果予以了验证,文字错率在独白场景里仅有1.49%,音画同步精度得到大幅提升,这意味着即便画面切换至风景,角色背对着镜头,配音也依旧能够卡在正确的时间点上。
模型架构怎么搭
“Fun”的输入途径极为灵活,你于一段视频以及文本台词的情形下,模型会合成与画面显示时间相互对齐的语音,又能够提供一个参考音色,使得模型克隆特定角色的声音,这样一种设计径直对标真实的配音流程,即配音导演先选定音色样本,随后让AI依据剧本生成整段对话。
模型会同时利用四类信息,分别是文本内容,声音特征,视觉画面,以及时间戳。这四者是相互补助的,当视觉信息缺少的时候,会由时间和文本进行兜底,当文本模糊的时候,会由画面和音色来进行校准。采用这种多模态融合的方式,使得Fun能够处理情绪化表达,以及镜头频繁切换。包括说话人快速轮换这些极为复杂的场面。
实测指标优于现有模型
阿里于自建的数据集之中开展了全面的评估,该评估涵盖了独白、旁白、对话以及多人场景。其结果表明,单人场景所呈现的效果是最为优异的,独白的中文字错率低至1.49%,旁白的中文字错率低至1.90%。这预示着模型在听写方面几乎不会出现差错,所生成的语音与画面契合得严丝合缝。
他们将Fun与另外两个开源配音模型一同进行对比测试,在词错率、唇部同步、时间对齐、音色相似度这四个指标方面,Fun均占据领先地位,对比测试更具说服力。尤其在时间对齐误差这一项目上,Fun能够把误差精准控制在毫秒级别,然而对比模型却常常出现语音相较于画面快半拍或者慢半拍的状况。
当存在多人对话的场景之际,这是Fun所具备的亮点之处。在当下,现有的模型于两人以上展开对话之时,常常会搞混淆谁应当在何时去说话。Fun凭借说话人分离的数据且引入时间模态,首次达成了双人和多人对话场景的稳定配音状态,虽说长视频的鲁棒性仍然有待于进一步提升,然而已然迈出了关键的一步。
开源范围和使用门槛
现已Fun完全地全方位平台实现开源状态,从事开发工作的人员能够于GitHub、ModelScope以及Hugging Face之上寻觅到代码以及模型。官方方面还推行开放了数据集样例,划分成中文与英文两个版本,以此便利从事开发工作的人员进行复现以及二次开发。网站所呈现的示例当中展示出了情绪化表达、镜头切换、面部遮挡等各种各样复杂情景之下的配音效果。
当前版本能够支持视频片段推理,其时长在30秒以内。对于专业制作而言,这样的时长着实有限,然而考虑到影视配音本就是逐句录制的,30秒足以涵盖大多数单句台词。现阶段的主要局限在于更长视频的稳定性会下降,并且模型在多人对话场景的鲁棒性也会随着时长增加而衰减。
应用场景和未来方向
客服、语音助手等领域中是通行了AI语音技术的,然而进入专业影视制作却始终是块难啃的硬骨头,影视配音对于声音的要求并非仅仅是与人声相似,还要与画面、情绪以及节奏达成完全的契合,Fun此次所供给的技术方案,至少在技术层面将“可用”的门槛给降低了。
对于短视频、动漫配音、游戏角色语音这些对成本敏感却要求专业效果的项目,眼下更适宜的应用场景便是如此。往后随着多模态大模型能力得到提升,那么着重突破的方向将会是处理长视频以及促使多人场景稳定性得以提升。要是能够把推理时长从30秒延长至几分钟,甚至是整集动画,如此一来AI在影视后期制作当中的角色,就会从“辅助工具”转变为“生产力工具”。
你平常在看动漫或者电影之际,可曾碰到过配音显著难以契合口型,又或者背景音与画面出现脱节的那种尴尬状况呢?去评论区谈论一下你记忆里最为深刻的“配音翻车”名场面吧。