
新闻资讯
英伟达发布Groq 3 LPX机架,专为智能体系统低延迟需求设计
机架。推理加速器,预计将在今年下半年面世。基础设施构建。带宽,显著提升解码(注:输出生成)速度、降低响应延迟。不足以覆盖任务需求时提供后援支持。倍的营收机遇。
英伟达于GTC 2026上推出的Groq 3 LPX机架,将AI推理的延迟降低至新低水平,对传统GPU在智能体系统里的统治地位直接发起挑战。该硬件是专门针对万亿参数模型设计的,拥有128GB片上SRAM以及40PB/s带宽,传递出一个清晰信号:未来AI的响应速度,由这种专用架构所决定。
全液冷机架的核心配置

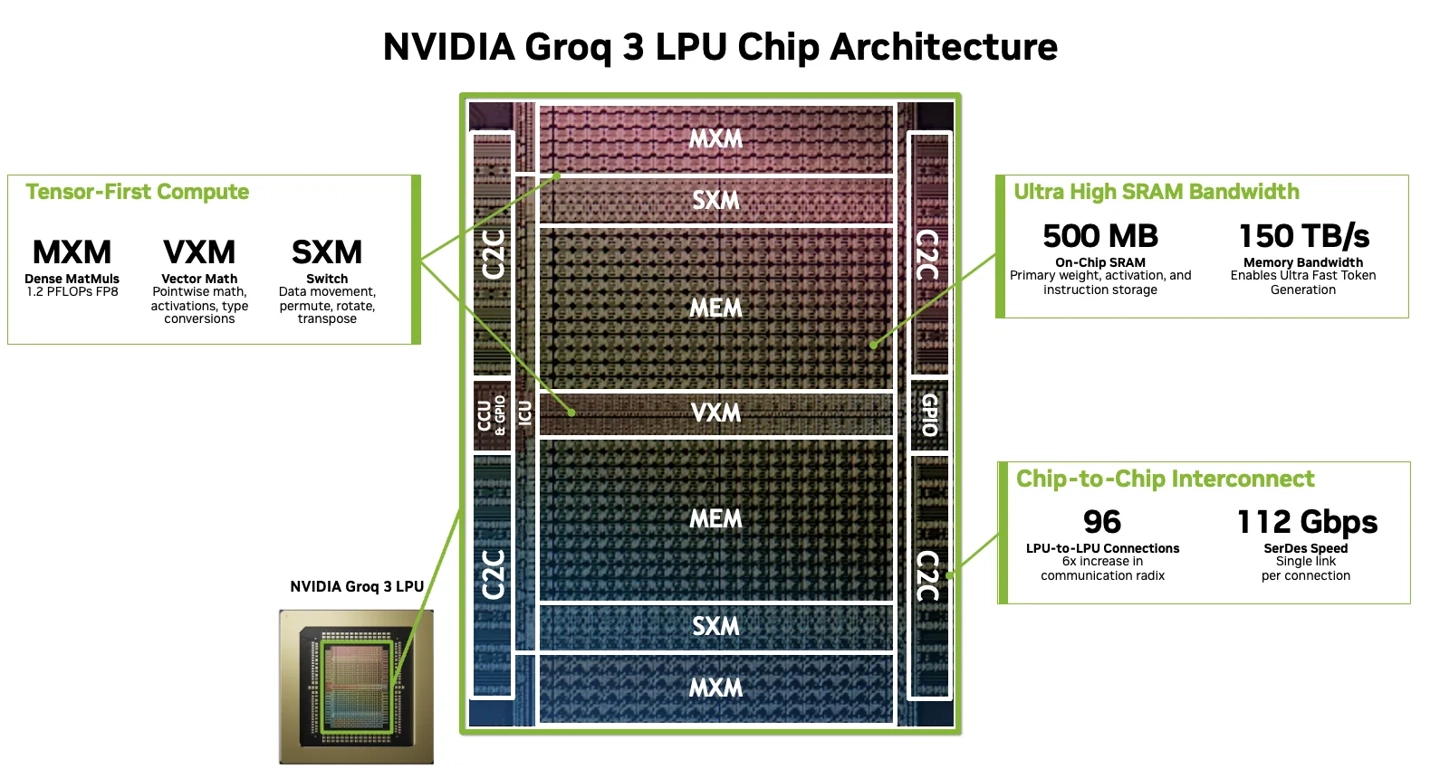
Groq 3 LPX结构的机架,是通过1U计算托盘进行堆叠的,整个机架之中容纳了32个这样的托盘,每个托盘的内部装有8颗Groq 3芯片,也就是LP30型号,因而整机总共使用了256颗LPU,这种布局紧凑的情况对散热的要求是极高的,英伟达直接采用了全液冷方案,将256颗芯片所产生的热量高效地带走,液冷管道在机架内部进行密集的排布,以此确保每一颗芯片都能够稳定地运行在高负载的状态下。
英伟达专门为模块化服务器设计的开放标准MGX基础设施,是这套配置的基础。Groq 3 LPX机架完全依照MGX规范搭建而成,这便意味着数据中心能够像搭积木那样集成这套系统,而无需对供电以及冷却设施进行额外改造。其机架高度、电源接口、数据线缆布局均已标准化,这大幅度地降低了部署门槛以及时间成本。
片上SRAM带来的带宽优势
每一枚 LP30 芯片里面设置有 500MB 的片上 SRAM,256 颗这样的芯片加起来便成为 128GB。此容量看上去并非很大,然而关键之处在于带宽达到了 40PB/s。SRAM 身为静态随机存取存储器,其速度相较于普通 DRAM 快出一个数量级。当模型权重以及数据都能够放置在片上之际,LPU 芯片能够直接从 SRAM 进行读取,越过对外部内存的访问,这是低延迟的核心源头。

在生成式AI任务里头,解码阶段的速度,直接对用户体验产生影响。Groq 3 LPX机架有着40PB/s的带宽,使得输出生成,几乎不会受到内存带宽的限制。对于像客服机器人、代码辅助工具这类需要实时交互的智能体应用而言,这样的响应速度,能够显著提升流畅度。跟传统GPU架构相比,后者在访问外部HBM时存有数百纳秒到微秒级别的延迟,而片上SRAM将这个时间压缩到了几纳秒。
外部DRAM的扩展支持
尽管片上SRAM速度快得惊人,然而128GB容量对于万亿参数模型而言并不充足。Groq 3 LPX的设计对该问题予以了考量,每颗LP30芯片具备96条C2C链路,这些链路用于与系统的其他部分相连接。通过这些链路,单个托盘能够借助结构扩展逻辑以及头节点CPU,扩展出384GB的DRAM内存。C2C属于英伟达自身的芯片互连技术,其延迟较低且带宽较高,能够确保在进行外部内存访问时的性能。
如果片上SRAM不够用,那么这套内外结合的存储架构会自动把部分数据迁移到DRAM,对于推理任务而言,模型的大部分参数或许驻留在DRAM中,而频繁被访问的激活值以及关键权重则留存于SRAM里,这种分层设计不但发挥了SRAM的速度优势,还解决了容量瓶颈,能使万亿参数模型在低延迟环境下运行。

对Vera Rubin平台的性能提升
英伟达将Groq 3 LPX认定作Vera Rubin平台的AI推理加速器,二者搭配起来成效明显。依据官方给出的数据,在添入这套机架之后,Vera Rubin平台于每兆瓦时的推理吞吐量提高了35倍。此一数字表明在相同功耗情形下,该系统能够处理的推理请求数量有了极大幅度的增多。对于数据中心运营商而言,这直接致使每笔推理交易的电费成本得以降低。
对于万亿参数模型而言,更关键之处在于,Groq 3 LPX开创了极为惊人的营收契机,其数量多达10倍之多。之所以会有这样的情况,背后的逻辑其实直白易懂:延迟越轻微,吞吐量越庞大,这就意味着能够承受数量更为可观的用户请求,与此同时,还能够确保服务的质量始终处于稳定状态。大模型厂商能够依据API调用的次数来进行收费,响应速度更为快捷,这使得单个硬件能够为更多客户提供服务,直接促使收入上限得到显著提升。英伟达所公布的这个数据,实际上就是在向市场表明:购置这套硬件设备,能够获取更为丰厚的收益回报。
智能体系统的低延迟需求
跟传统聊天机器人不一样的是智能体系统,那里边儿,前边儿的那个需要连续去执行好多步操作,这是它们两者间的区别所在,举个例子来说,就像有一个AI助手要去预订机票,它可能首先得去查询一下航班,接着再去对比一下价格儿,最后才能够完成支付,这里边儿的每一步都得要快速地做出响应才行,如果说产生的延迟过高的话,那么整个流程看起来就会显得特别卡顿,用户很难去接受这样的情况,Groq 3 LPX的架构恰恰是专门儿针对这种多轮交互的场景做了优化,以此来保证每个子任务都能够在毫秒级这样的时间范围内完成。
智能体系统的刚需之中包含长上下文,在处理复杂任务之际,AI有必要记住全程对话历史以及中间结果,上下文长度常常达到几十万tokens在处理复杂任务之时,Groq 3 LPX具备的高带宽SRAM能够迅速存取这些上下文数据,不会由于内存带宽不足致使速度被拖慢,这种能力能够让智能体得以处理更为复杂的任务,比如说撰写篇幅较长的文档,分析多份合同,开展深度研究等。
预计上市时间与市场定位
英伟达于GTC 2026时宣告,Groq 3 LPX机架会于今年下半年面市,此时间节点选在Vera Rubin平台铺开之后,显然是当作补充方案推向市场,从其定位来讲,它并非替代传统GPU,而是专门针对推理场景予以优化,对于那些早就已部署Vera Rubin用于训练的用户而言,添置Groq 3 LPX机架能够形成训练推理一体化的完备方案。

于市场竞争范畴而言,Groq 3 LPX所直接对标之物乃是其他AI专用芯片,诸如Cerebras的晶圆级引擎、SambaNova的流式架构这般。这些产品皆在对低延迟推理市场展开争夺。英伟达借由Vera Rubin平台与Groq 3 LPX的组合,既保留住啦通用计算的灵活性,又于专用推理方面构建起了优势。对于数据中心来讲,选取这套方案便意味着能够运用统一品牌的基础设施去覆盖从训练直至推理的全链条。
你认为于AI推理加速范畴之中,是具备专用架构的Groq 3 LPX更具前景,还是通用GPU的不断迭代更能够契合未来所需,欢迎在评论区域之内分享你的见解,点赞并进行转发从而让更多的人得以看到这场硬件方面的争论。