新闻资讯
美团发布音频生成模型 音色克隆效果突破上限
音色克隆上限”。引擎长期受困于“多阶段”的复杂流程:先预测中间声学特征(如梅尔频谱),再依赖一个独立的神经声码器将特征“翻译”成最终波形。Transformer(DiT),在波形隐空间里完成声音的压缩、建模与重建。拥有高效的下采样与多尺度建模、非参数捷径稳定训练以及对抗式多目标训练等多维度创新。
美团的此项技术突破,直接化解了传统TTS模型合成声音时细节遗失的痛点,以往那些繁杂的多阶段流程被全然简化,这表明AI生成的声音会更逼真、更自然,不复有那种机械感。
彻底告别梅尔谱 一个模型打通全部流程
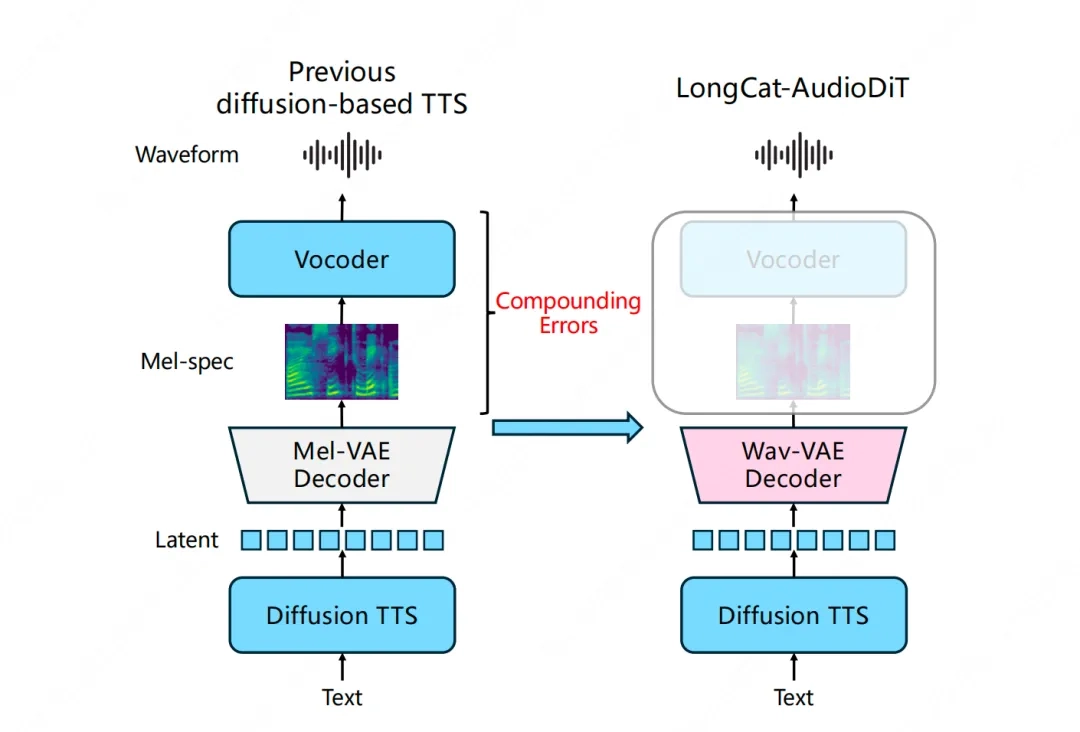
主流的TTS技术曾是过去的,像2024年众多公司采用的方案那般,都需先对梅尔频谱予以预测。这恰似先要画出一张草图,随后借助另一个唤作“神经声码器”的工具将草图绘制成彩色画作。整个进程划分成了两步,两个步骤运用的并非是同一种语言,传话之时不免会出现差错。
2026年4月1日,美团所发布的新模型,彻底摒弃了这个老办法。它径直于波形潜空间之中作业,借由一个模型达成声音的压缩、建模以及生成。此项改变恰似往昔需从A地乘火车至B地而后转乘汽车,现今有了直达高铁,省却了中间换乘的繁杂与可能出现的延误。

两大核心部件 Wav-VAE与DiT协同工作
崭新的模型仅仅运用了两个核心部件,其结构着实非常简单。其中第一个部件是波形变分自编码器,该部件负责将复杂的声音波形进行高效压缩,进而提取出最为重要的声音特征。第二个部件是扩散变换器,此部件负责在经过压缩的空间之内重建声音,以此保证所生成的声音既清晰又自然。
美团的技术团队于研发期间进行了涵盖多维度的创新,达成了高效的下采样以及多尺度建模,此二者可令模型同时留意声音的细节与整体结构,非参数捷径使训练过程得以稳固,避免模型出现偏差,对抗式多目标训练致使生成的声音更为真切,难以被辨别为AI合成的。
骨干网络深度优化 训练更稳定效果更好
多项结构优化组成了新模型的骨干网络,其中全局自适应层归一化技术,会依据各异的输入自行调节参数,从而使模型适配各种声音特性,此外,QK正则化与旋转位置编码技术稳固了注意力训练,化解了长序列建模期间的注意力分散难题。
这些于2026年上半年在AI语音领域极为前沿的技术优化,美团的技术报告表明,借助这些改进,模型在处理长达30秒的复杂语音之际,仍可维持音色的高度一致,即便为带有口音或呈现情绪波动的说话风格,模型也能够精准捕捉并完美复现。
双重约束机制 修复训练推理不匹配问题
面临这样一个棘手的状况,即传统流匹配TTS模型存在着一个由来已久的严重问题,那就是在进行训练期间所使用的数据,与在实际投入使用时所碰到的数据,二者并不相同,这情形宛如在健身房里借助标准器械能够练得颇为出色,然而一旦到了野外攀爬真正的山峰时,却发现根本施展不出力气,而这种不匹配的情况会致使在合成声音的时候出现卡顿现象或者导致音质下降。
美团新推出的模型,引入了一种双重约束的机制,此机制专门用来修复那个漏洞,它从两个不一样的角度,对生成的过程予以限制,以此确保模型在实际投入使用的时候,其表现能够和训练的时候保持同样良好的状态,这样的一个突破使得模型在面对那些从未见过的文本以及说话人之际,依旧能够稳定地输出高质量的音频。

性能数据亮眼 3.5B版本多项指标领先
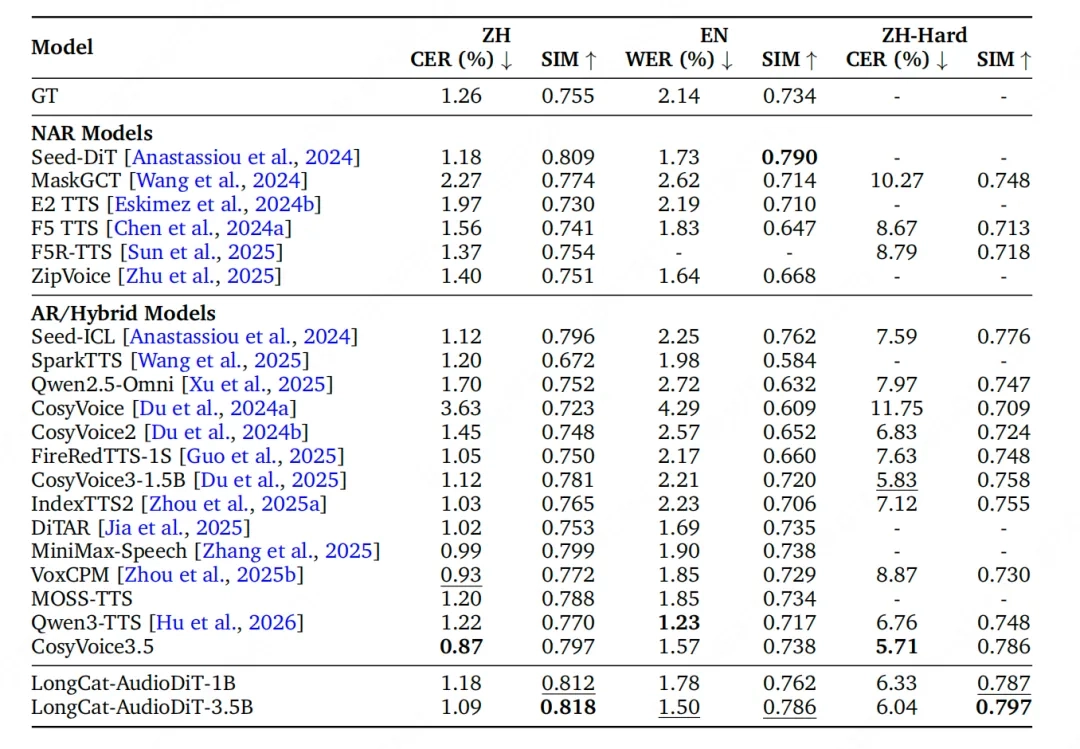
于专业测试集Seed-ZH之上,3.5B参数版本具备的说话人相似度达成了0.818。这究竟是何种概念呢?它此满分是1分呀 ,处于0.8以上已然属于极为高的水平喽 ,这其中意味着AI克隆产出的声音跟原声近乎很难辨别区分开来。而在更为困难的Seed-Hard测试集当中 ,其得分居然也达到了0.797。
Seed-TTS、FireRed-2.5、MaskGCT等颇具知名度的模型,被这个成绩给超越了,2026年4月2日所公开的数据表明,新模型于音色克隆的准确性之层面以及自然度这一方面,均树立起了全新的行业标准,无论短句,还是长达数分钟的段落,克隆出来的声音均可维持高度的稳定。
模型已开源 开发者可自由下载使用
美团已把这个新模型予以开源,给出了1B以及3.5B这两个参数版本,1B版本适宜在计算资源受限的环境里迅速部署,像手机端或者边缘设备,3.5B版本则适宜于追求最高音质的服务器端应用,像有声读物制作或者虚拟数字人配音。
开放源码的链接,于二零二六年四月一日被公布了。那些开发者能够自由自在地去下载模型的权重,进而展开二次开发,或者直接把它集成到自身的产品里面。此项技术会极大程度地降低高质量语音合成的门槛,使得更多的中小团队也能够制作出可与大厂相媲美的TTS应用。
存不存在那种无比酷似真人的 AI 配音被你碰到过呀?抑或是你对音色克隆技术于娱乐、教育等范畴开展的应用抱有着何种期待呢?欢迎于评论区当中呈现出你的看法,点赞转发,从而让更多人知晓这一技术突破。