
新闻资讯
新一代大语言模型跨多轮对话表现不佳,测试有这些问题
及后续版本开始)在任务需要跨多轮对话完成时,表现依然不佳。原始研究发现,调低温度值(temperature)这类技术微调无法解决这一问题。研究人员建议:一旦出现异常,重新开启一段新对话,最好先让模型把所有请求总结一遍,再用这份总结作为新对话的起点。
可能是你这边的对话历史在拖累最新的AI大模型的智商,像GPT-5等新一代模型于处理要多轮对话才可搞定的任务之际,性能会大幅下滑,在某些场景当中准确率直接下降至七折。
对话越长脑子越乱
当信息如平日里聊天那般分不同次发送给AI之际,它的表现远远比不上你把所有需求一次性整个抛出来的情况。菲利普·拉班团队开展的研究,就信息的“分片式”输入跟“拼接式”输入做了对比,其结果让人十分震惊。
模型的性能在代码编写、数据库查询、数学计算等六个核心任务当中,出现了如雪崩般的下滑情况。哪怕是最新的GPT - 5系列,性能降幅从老版本的39%,稍微收窄至33%,然而这表明模型依旧失去了三分之一的“智商”。
文本摘要成了重灾区
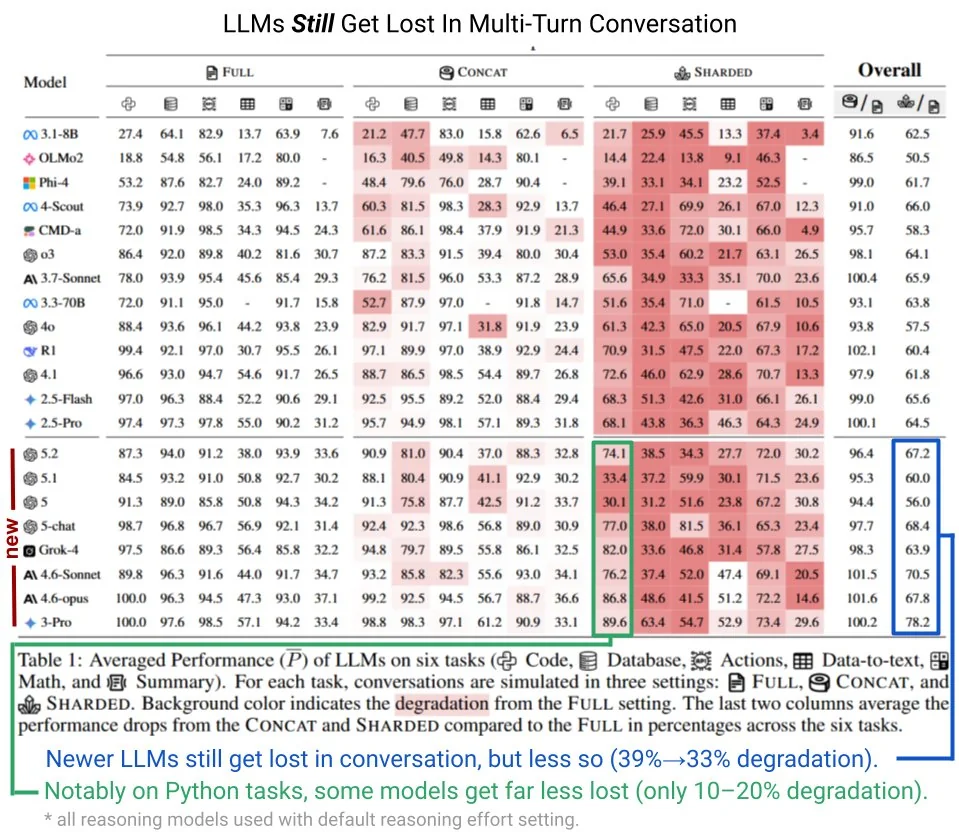
在六项测试任务里头,文本摘要任务展现出来的表现是最叫人担忧的。当被要求让模型多次去阅读文章片段然后再生成摘要的时候,部分模型所出现的性能损失达到了颇为惊人的幅度,这几乎使得AI丧失了对总结归纳的基本能力。
研究人员经发现得出,模型于处理分片信息之际,极难如同人类那般有效地整合前后文逻辑,它好像会“忘却”早期对话里的细节,或者在整合信息当中产生逻辑混乱,致使最终生成的摘要质量远远比不上一次性处理全文。
实际操作指令反而最稳
并不是所有任务都糟糕透顶。在操作指令这类任务当中,AI表现还算挺得住,部分模型仅仅损失了10%至20%的性能。这或许是由于的是指令本身具备较强结构特性所致原因,逻辑链条相对清晰。
纵使这样,百分之二十的性能折损于实际运用当中仍旧不可轻视。比如说,你叫AI分阶段帮你配置一个繁杂的软件,要是中途须要调整参数,它极有可能会在后续阶段里迷失方向,致使整个配置流程失败。
真实场景比实验室更残酷
拉班专门强调,他们所做的测试单单采用了简易的用户模拟,然而实际的应用场景可要繁杂许多。要是于真实的对话里,用户鉴于获取到新的信息进而在中途转变想法,那么AI的性能下降程度或许会远远超过实验室数据所体现的程度。
这就如同是一个参与会议的辅助人员,你把参会人员发生的变动,分作次数说了好多回。将议程做出的调整,也分作次数告知了它。最终它帮你安排出来的会议时间,和会议地点,很有可能已然是完全不匹配了。现实当中对话所具备的随意与不确切性质,对于人工智能而言,是一项极大的考验。
调参数救不了场
诸多用户惯于凭借调节温度值等参量前来施行“优化”AI的作答之举,然而对此开展的研究却揭示出,此类技术微操针对旨在解决牵涉多轮对话的讯息整合难题而言,全然不具备任何效用。温度值主要发挥对于创造性的影响作用,可是模型目前所匮乏欠缺缺乏的却是记忆以及整合能力。
这表明,问题居于更深层次的架构之中。不管是使温度降低,进而让回答更为保守,又不论是促使温度提升,由此增加随机性,这两种做法都没办法助力人工智能,将零散分布在多轮对话里的信息碎片,拼凑成完整的认知图景。
开新对话才是最佳出路
棘手问题当前,研究团队呈一極具实用价值之建议:一旦察觉对话趋向异常或者成效欠佳,便毫不犹豫果断开启全新一段对话。于操作层面而言,你能够先行促使模型将之前全部对话之请求以及关键信息予以总结一番。
拿到此份总结之后,径直复制其作为新对话的起始点,这等同于协助AI进行了一回内存清理以及重点提示,使得它能够于一个“洁净”的上下文当中,依据你梳理妥当的完整信息再度开启工作,效果一般而言会好出许多。
你有没有碰到过那种跟AI交流着交流着,它就开始出现错乱状况的情形呢?欢迎来评论区把你的失败经历分享出来,给本文点赞并且转发它,使得更多人掌握怎样正确操控AI。